Following the release of the Linux Kernel 4.12, which for the first time brings the KASLR feature enabled by default, and almost simultaneously the announcement of a feature called KARL in OpenBSD, I found it interesting to clarify the differences between these security techniques, since I think that the combination of both will be very important in the future of system security as they will prevent exploiting vulnerabilities related to memory corruption (buffer-overflow).
But before entering to detail the KASLR and KARL features let’s take a look to ASLR.
ASLR
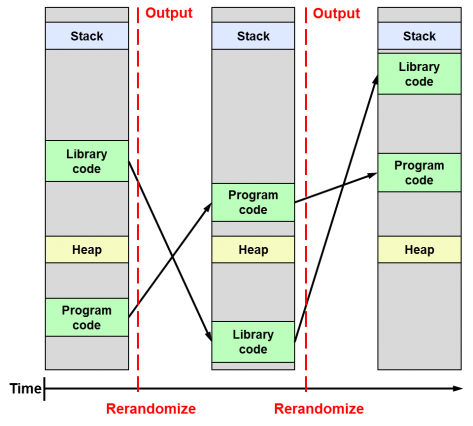
The term ASLR refers to Address Space Layout Randomization. It is a technique aimed at preventing an attacker who previously knows that a program function is vulnerable and can be exploited, to get access to it by preventing him from knowing the memory address where that function is allocated within the running process. This is possible because ASLR basically consists of randomly distributing the fundamental parts of a process (executable base, stack pointers, libraries, etc.) into the memory address space that has been assigned to it by the operating system.
Error: Your Requested widget " ai_widget-6" is not in the widget list.
- [do_widget_area above-nav-left]
- [do_widget_area above-nav-right]
- [do_widget_area footer-1]
- [do_widget id="wpp-4"]
- [do_widget_area footer-2]
- [do_widget id="recent-posts-4"]
- [do_widget_area footer-3]
- [do_widget id="recent-comments-3"]
- [do_widget_area footer-4]
- [do_widget id="archives-4"]
- [do_widget_area logo-bar]
- [do_widget id="oxywidgetwpml-3"]
- [do_widget_area menu-bar]
- [do_widget id="search-3"]
- [do_widget_area sidebar]
- [do_widget id="search-4"]
- [do_widget id="ai_widget-2"]
- [do_widget id="categories-5"]
- [do_widget id="ai_widget-3"]
- [do_widget id="ai_widget-4"]
- [do_widget id="ai_widget-5"]
- [do_widget_area sub-footer-1]
- [do_widget id="text-4"]
- [do_widget_area sub-footer-2]
- [do_widget_area sub-footer-3]
- [do_widget_area sub-footer-4]
- [do_widget_area upper-footer-1]
- [do_widget id="search-2"]
- [do_widget id="recent-posts-2"]
- [do_widget id="recent-comments-2"]
- [do_widget id="archives-2"]
- [do_widget id="categories-2"]
- [do_widget id="meta-2"]
- [do_widget_area upper-footer-2]
- [do_widget_area upper-footer-3]
- [do_widget_area upper-footer-4]
- [do_widget_area widgets_for_shortcodes]
- [do_widget id="search-5"]
- [do_widget id="ai_widget-6"]
- [do_widget_area wp_inactive_widgets]
- [do_widget id="wpp-2"]
- [do_widget id="text-1"]
- [do_widget id="recent-posts-3"]
- [do_widget id="categories-3"]
- [do_widget id="archives-3"]
- [do_widget id="icl_lang_sel_widget-3"]
Thus, an attacker will never know for sure how to access a function and will not be able to exploit it. If he tries to do it by brute force, chances are that he will crash the process and not be able to continue with his attack.
The ASLR technique has been around for a long time. It was introduced in Linux as a patch in 2001 and is part of the kernel since 2005. It was later introduced in Windows Vista and Mac OS X 10.5 (Leopard) in 2007 and finally in iOS and Android in 2011.
KASLR
What KASLR does is simply add the kernel ‘k’ to the ASLR technique seen before, ie, randomize the kernel code location in memory when the system boots. KASLR was introduced in the Linux kernel some time ago with version 3.14 (2014), but it is now in 2017 with the recent release of version 4.12 when it has been enabled by default.
Unfortunately, its effectiveness has been questioned and is still under discussion today. This is because in order to overcome the protection offered by the ASLR technique and get an attack to materialize it is required to succeed in any of the following operations:
- Try by brute force to find the random addresses that the attacker pursues, which will require re-running the application process every time it crashes, which will alert the system administrator.
- Gain certain key pointers that provide information about the process allocation in memory.
The second scenario is quite feasible in the case of operating systems, because due to some hardware configuration limitations the kernel may have limited address space available, but especially because the kernel can not change its distribution in memory throughout its operating time, ie until the next time the system is restarted a new random distribution in memory will not be performed.
Error: Your Requested widget " ai_widget-6" is not in the widget list.
- [do_widget_area above-nav-left]
- [do_widget_area above-nav-right]
- [do_widget_area footer-1]
- [do_widget id="wpp-4"]
- [do_widget_area footer-2]
- [do_widget id="recent-posts-4"]
- [do_widget_area footer-3]
- [do_widget id="recent-comments-3"]
- [do_widget_area footer-4]
- [do_widget id="archives-4"]
- [do_widget_area logo-bar]
- [do_widget id="oxywidgetwpml-3"]
- [do_widget_area menu-bar]
- [do_widget id="search-3"]
- [do_widget_area sidebar]
- [do_widget id="search-4"]
- [do_widget id="ai_widget-2"]
- [do_widget id="categories-5"]
- [do_widget id="ai_widget-3"]
- [do_widget id="ai_widget-4"]
- [do_widget id="ai_widget-5"]
- [do_widget_area sub-footer-1]
- [do_widget id="text-4"]
- [do_widget_area sub-footer-2]
- [do_widget_area sub-footer-3]
- [do_widget_area sub-footer-4]
- [do_widget_area upper-footer-1]
- [do_widget id="search-2"]
- [do_widget id="recent-posts-2"]
- [do_widget id="recent-comments-2"]
- [do_widget id="archives-2"]
- [do_widget id="categories-2"]
- [do_widget id="meta-2"]
- [do_widget_area upper-footer-2]
- [do_widget_area upper-footer-3]
- [do_widget_area upper-footer-4]
- [do_widget_area widgets_for_shortcodes]
- [do_widget id="search-5"]
- [do_widget id="ai_widget-6"]
- [do_widget_area wp_inactive_widgets]
- [do_widget id="wpp-2"]
- [do_widget id="text-1"]
- [do_widget id="recent-posts-3"]
- [do_widget id="categories-3"]
- [do_widget id="archives-3"]
- [do_widget id="icl_lang_sel_widget-3"]
Thus, at the time an attacker gets a pointer to the kernel memory distribution table he will have managed to skip this defense barrier. And that is exactly what makes it a very weak technique and the main reason for controversy, since while ASLR is a very interesting technique for application security, many authors claim that it is not appropriate to apply it at the kernel level.
KARL
![]() And that is when the implementation of KARL (Kernel Address Randomized Link) that has recently been released in OpenBSD emerges as a promising solution to the above problems, although it should be noted that they are of a different nature, since KARL is not based on a random distribution in memory (ASLR) and still located in the same fixed addresses of KVA (Kernel Virtual Address Space).
And that is when the implementation of KARL (Kernel Address Randomized Link) that has recently been released in OpenBSD emerges as a promising solution to the above problems, although it should be noted that they are of a different nature, since KARL is not based on a random distribution in memory (ASLR) and still located in the same fixed addresses of KVA (Kernel Virtual Address Space).
This fixed position meant that before KARL the kernel was always the same and was in the same place for all users. The innovation introduced by KARL is that kernel binary files are generated by distributing the kernel’s internal files in a random order each time the system is restarted or updated, so each system will work every time it is booted with a unique kernel totally different from other systems at binary level. This considerably hinders an attacker’s task when exploiting internal kernel functions, pointers, and objects.
Therefore, the main difference between KASLR and KARL is that KARL loads a different kernel at a binary level each time and places it at the same place in memory, whereas KASLR always loads the same binaries but each time at a different and random location of memory. This is the same goal, but following different approaches.
So far it may seem that KARL does not represent a great improvement over the limitations that KASLR already had, since once the distribution in memory of this random kernel is known its vulnerabilities could be exploited in the same way until the next reboot. The real news is that for the first time both techniques can be combined so that even if an attacker obtains the random memory address where the kernel starts (a process made difficult by KASLR), it can not be used to know where certain functions are located since their place in memory will also be random and will differ from system to system.
Hopefully soon we can see a KARL implementation on Linux and Windows, which will undoubtedly help improve the security of these operating systems.
More details on the recent implementation of KARL in OpenBSD here:
1 comment
Join the conversationRott - 24/07/2019
Excellent article, very clear and concise. Thanks!