Platforms hosting virtual events face a unique and exceptionally complex technical challenge: all traffic concentrates in an avalanche during the few minutes before the event starts. Users arriving simultaneously, authenticating, loading 3D scenes, and establishing real-time data connections. Within seconds, the system must scale from near zero to thousands of concurrent users without perceptible service degradation.

Virtway Metaverse needed a solution that would transform their AWS infrastructure to support this aggressive traffic pattern without compromising user experience or skyrocketing operational costs. As cloud architect, I designed and implemented a complete solution combining Aurora Serverless v2 with multi-layer hybrid autoscaling, RDS Proxy optimization for efficient connection multiplexing, and advanced vertical and horizontal scaling strategies.
The Challenge: Traffic Avalanches at Scheduled Events
Traditional web applications experience gradual traffic growth. Virtual event systems like Virtway Metaverse face a radically different scenario:
Characteristic traffic pattern:
- Normal state: controlled and predictable load between events (minimal capacity).
- Pre-event (T-5 minutes): eager users start connecting early.
- Event start (T+0): massive avalanche in under 60 seconds (0 → 100% in < 1 minute).
- During event: stable, sustained load with thousands of concurrent users.
- Event end: gradual decline as users leave the session.
Optimization opportunities identified:
The solution: completely reengineered AWS architecture with intelligent multi-layer autoscaling, deep connection optimization and clear separation of component responsibilities.
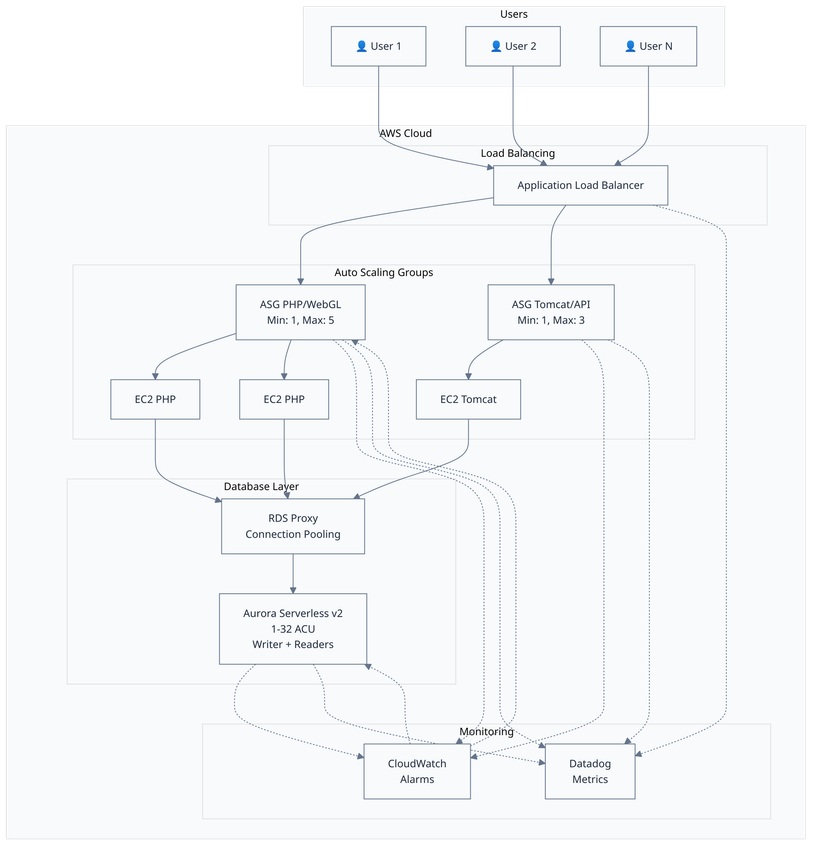
Solution Architecture
I designed a highly optimized hybrid AWS architecture combining ultra-fast vertical scaling, intelligent horizontal scaling and efficient database connection management.
Core Components
| Component | Technology | Purpose |
|---|---|---|
| Database | Aurora Serverless v2 (PostgreSQL) | Auto-scalable database with variable ACU capacity (1-32 ACU) |
| Connection pooling | AWS RDS Proxy | Intelligent connection multiplexing to reduce Aurora load |
| Application layer | EC2 Auto Scaling Groups (PHP + Tomcat) | Web servers and API with automatic scaling |
| Load balancing | Application Load Balancer | Traffic distribution and health checks |
| Monitoring | CloudWatch + Datadog | Metrics, alarms and observability |
| Infrastructure as code | Terraform | Reproducible and versioned infrastructure management |
Architecture Diagram
Solution 1: Aurora Serverless v2 with Hybrid Autoscaling
Why Aurora Serverless v2 instead of traditional RDS PostgreSQL?
Choosing Aurora Serverless v2 over traditional RDS PostgreSQL was strategic and directly addresses Virtway’s avalanche traffic pattern:
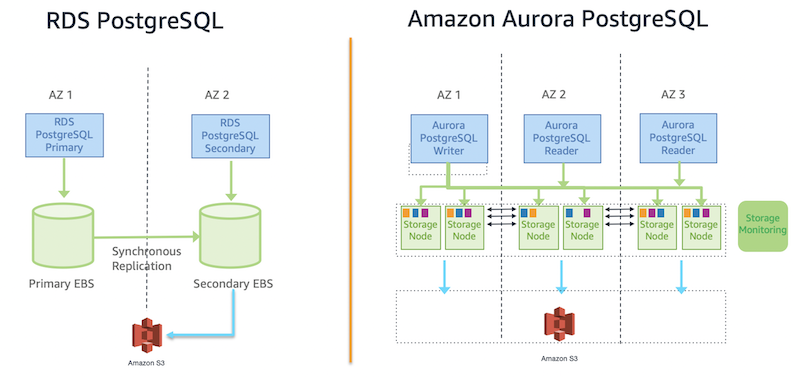
Key architectural differences: Aurora separates compute and storage, allowing independent scaling of each layer. Traditional RDS has both layers coupled, limiting scaling flexibility.
Critical Aurora advantages for this use case:
This architecture enabled the multi-layer hybrid autoscaling implementation that proved critical for handling traffic avalanches.
Multi-Layer Autoscaling Strategy
I implemented a 3-layer hybrid autoscaling system combining different strategies to respond with exceptional speed to traffic spikes:
![]()
![]()
Layer 1: Target Tracking (AWS-Managed) - Automatic baseline
- Metric: RDSReaderAverageCPUUtilization
- Target: 30% CPU (aggressive to anticipate spikes)
- Scale-out cooldown: 30 seconds
- Scale-in cooldown: 2 minutes
- Benefit: AWS automatically calculates optimal scaling actions
Layer 2: Step Scaling (Manual, Aggressive) - Extreme spike response
- CPU >70% alarm: adds 1 reader immediately
- CPU >85% alarm: adds 2 readers simultaneously
- Period: 30 seconds (ultra-fast detection)
- Evaluation: 1 period (immediate action without delays)
- Benefit: aggressive response in under 1 minute
Layer 3: Multi-Metric (Proactive) - Early detection before reaching maximum capacity
- Connections >280 alarm: scales before historical peak of 391 connections (70% of observed maximum)
- Latency >3ms alarm: detects degradation before users perceive it (75% of 3.8ms peak)
- Benefit: preventive scaling before CPU becomes the bottleneck
Vertical Capacity Optimization
I significantly increased the ACU (Aurora Capacity Units) range to allow more aggressive vertical scaling:
| Metric | Before | After | Improvement |
|---|---|---|---|
| Max ACU per instance | 20 | 32 | +60% |
| Max total capacity | 60 ACU | 96 ACU | +60% |
| Effective CPU threshold | 40% | 30% | Anticipated response |
Critical benefit: vertical scaling occurs in seconds, while horizontal requires 8 minutes to provision readers. This additional capacity keeps the system stable during the horizontal provisioning window.
Optimized Autoscaling Results
Solution 2: RDS Proxy and Connection Optimization
Pinned Connections Diagnosis and Resolution
A key optimization opportunity identified was pinned connections: connections that RDS Proxy could multiplex more efficiently by eliminating session state (temporary variables, temporary tables, session configuration).
Deep investigation performed:
- Detailed analysis of RDS Proxy logs identifying pinning patterns.
- Low-level debugging of queries causing unintentional pinning.
- Exhaustive application code review to eliminate unnecessary session state usage.
- Validation of Aurora cluster policies to ensure correct traffic routing.
Optimizations implemented:
- Strict traffic separation: read queries exclusively to Reader Endpoint, transactions to Writer.
- Session state elimination: code refactoring to avoid session variables and temporary tables usage.
- Aurora sequence configuration: autoincrement management adjustments for high concurrency.
- Optimized cluster policies: rule definition for correct failover and high availability.
Proxy Optimization Results
Solution 3: EC2 Autoscaling Optimization
Multi-Layer Architecture for EC2 Instances
I implemented a 4-layer autoscaling system for EC2 groups (PHP/WebGL and Tomcat/API):
Layer 1: Target Tracking - CPU (Safety net)
- Target: 70% CPU utilization
- Response: 2-4 minutes
Layer 2: Target Tracking - ALB Requests (Primary)
- APP Target: 1,000 requests/min per instance
- WAPI Target: 800 requests/min per instance
- Response: 1-3 minutes
Layer 3: Step Scaling (Extreme bursts)
- High Load (1,800 req/min): +2 instances
- Extreme Load (2,200+ req/min): +3 instances
- Cooldown: 60 seconds
Layer 4: Scheduled Scaling (Pre-event)
- Scale-up 15-30 min before event
- Capacity ready when users arrive
- Eliminates manual pre-scaling
Autoscaling Groups Reengineering
I identified a significant optimization opportunity: separating the Tomcat service from EC2 instances dedicated exclusively to PHP/WebGL, even those dedicated exclusively to PHP/WebGL.
Solution implemented:
- Intelligent logic configuration in user-data to start Tomcat only on correct ASG instances.
- Clear responsibility separation between PHP (frontend/WebGL) and Tomcat (API/backend) groups.
- Dynamic Tomcat connection pool configuration based on ASG size and DB capacity.
Benefits obtained:
- CPU/memory resource liberation on PHP servers.
- Optimization of database connections from PHP machines.
- Better load distribution and efficient resource usage.
- Cost reduction by not running unnecessary services.
Additional Optimizations
Improved Monitoring and Observability
Infrastructure as Code with Terraform
I managed all infrastructure with Terraform, ensuring:
- Reproducibility: completely coded and versioned infrastructure.
- Consistency: same configuration in development and production.
- Auditability: complete change history in version control.
- Documentation: code as living documentation of the architecture.
Results and Business Impact
Performance and Availability Improvements
Operational Cost Optimization
Operations Impact
Key Technical Achievements
Lessons Learned
What worked exceptionally well:
- Multi-layer hybrid autoscaling - Combination of Target Tracking, Step Scaling and Multi-Metric provided optimal response to different traffic scenarios.
- Aggressive vertical scaling - Increasing max ACU to 32 provided essential buffer during horizontal provisioning.
- Proactive monitoring - Alarms based on real historical data (connections >280, latency >3ms) allowed anticipating capacity needs.
- Infrastructure as code - Terraform ensured consistency, reproducibility and living documentation of the architecture.
- Responsibility separation - Architectural PHP/Tomcat cleanup freed resources and simplified debugging.
Technical optimizations performed:
- Pinned connections diagnosis - Required deep low-level analysis of RDS Proxy logs and application code refactoring.
- Alarm threshold tuning - Production data-based iteration to find optimal points between false positives and fast response.
- Aurora provisioning limitation - The 8 minutes to add reader is AWS limitation, compensated with more aggressive vertical scaling.
- Multiple layer coordination - Ensuring autoscaling layers don’t interfere harmoniously.
- Production testing - Validation during real high-load events, requiring intensive monitoring and fast rollback capability.
Conclusion
This AWS infrastructure optimization project for Virtway Metaverse represents an exceptional case study on how to design highly resilient cloud architectures for event-driven traffic patterns with extreme spikes. By combining Aurora Serverless v2 with multi-layer hybrid autoscaling, deep RDS Proxy optimization and complete EC2 autoscaling reengineering, I developed a robust platform capable of supporting thousands of simultaneous users without perceptible degradation, with high availability and optimized response times.
The resulting architecture establishes a solid foundation for future growth. The system now scales automatically anticipating demand, keeps costs under control through aggressive scale-in and provides complete operational visibility for continuous analysis and optimization.
Key Takeaways for Similar Projects
- Event-driven architectures require multi-layer autoscaling combining immediate response (Step Scaling), automatic management (Target Tracking) and proactive anticipation (Multi-Metric).
- RDS Proxy requires careful optimization - eliminating pinned connections maximizes multiplexing benefits.
- Vertical scaling as buffer for horizontal scaling - Aurora Serverless v2 variable ACU compensates for 8-minute reader provisioning.
- Multi-dimensional monitoring is essential - CPU alone isn’t sufficient, you need connections, latency and multiple metrics to anticipate capacity needs.
- Clear responsibility separation - Clean PHP/Tomcat architecture facilitates debugging, optimization and independent scaling.
Need to optimize your AWS infrastructure?
If your application faces similar challenges:
- Extreme traffic spikes that saturate your infrastructure.
- Scalability problems with databases under heavy load.
- Intermittent errors during events or peak demand moments.
- Growing AWS costs without proportional performance improvements.
- Legacy architecture requiring modernization for high availability.
As an AWS cloud architect with 20+ years of experience, I can help you design and implement scalable solutions that support your most demanding workloads while keeping costs under control.
Specialized in Aurora Serverless v2, intelligent autoscaling, RDS Proxy optimization and high-availability event-driven architectures.
Get in touch →

About the author
Daniel López Azaña
Tech entrepreneur and cloud architect with over 20 years of experience transforming infrastructures and automating processes. Specialist in AI/LLM integration, Rust and Python development, and AWS & GCP architecture. Restless mind, idea generator, and passionate about technological innovation and AI.
Related projects
Optimalway: AWS Infrastructure & Optimization
Scalable AWS infrastructure with auto-scaling for PHP/Java apps, MongoDB optimization, and Apache/PHP-FPM/Tomcat performance analysis. Trusted cloud partner.

AWS Infrastructure Security with Advanced Bastion Host, 2FA and Access Auditing
Implementation of AWS security architecture with bastion host as single entry point, two-factor authentication with Google Authenticator, role-based access control, encrypted SSH tunnels for internal services and complete session recording system for regulatory compliance.

11-Year AWS Infrastructure Partnership - Complete System Administration for Web Hosting Company
Decade-long AWS infrastructure management delivering 99.9% uptime through proactive monitoring, crisis response, cost optimization, and seamless business transition. A professional relationship built on trust, pragmatic solutions, and continuous evolution.
Comments
Submit comment