Las plataformas que organizan eventos virtuales enfrentan un desafío técnico único y extremadamente complejo: todo el tráfico se concentra en avalancha durante los pocos minutos previos al inicio del evento. Usuarios que llegan simultáneamente, se autentican, cargan escenas 3D y establecen conexiones de datos en tiempo real. En cuestión de segundos, el sistema debe escalar desde carga controlada entre eventos hasta miles de usuarios concurrentes sin degradación perceptible del servicio.

Virtway Metaverse necesitaba una solución que transformara su infraestructura AWS para soportar este patrón de tráfico tan agresivo sin comprometer la experiencia del usuario ni disparar los costes operativos. Como arquitecto cloud, diseñé e implementé una solución completa que combinó Aurora Serverless v2 con autoscaling híbrido multi-capa, optimización de RDS Proxy para multiplexación eficiente de conexiones y estrategias avanzadas de escalado tanto vertical como horizontal.
El desafío: avalanchas de tráfico en eventos programados
Las aplicaciones web tradicionales experimentan un crecimiento gradual de tráfico. Los sistemas de eventos virtuales como Virtway Metaverse enfrentan un escenario radicalmente diferente:
Patrón de tráfico característico:
- Estado normal: carga controlada y previsible entre eventos (capacidad mínima).
- Pre-evento (T-5 minutos): inicio de conexiones anticipadas de usuarios entusiastas.
- Inicio evento (T+0): avalancha masiva en menos de 60 segundos (0 → 100% en < 1 minuto).
- Durante evento: carga estable y sostenida con miles de usuarios concurrentes.
- Fin evento: descenso gradual conforme los usuarios abandonan la sesión.
Oportunidades de optimización identificadas:
La solución: arquitectura AWS completamente rediseñada con autoscaling inteligente multi-capa, optimización profunda de conexiones y separación clara de responsabilidades entre componentes.
Arquitectura de la solución
Diseñé una arquitectura híbrida AWS altamente optimizada que combina escalado vertical ultrarrápido, escalado horizontal inteligente y gestión eficiente de conexiones de base de datos.
Componentes principales
| Componente | Tecnología | Propósito |
|---|---|---|
| Base de datos | Aurora Serverless v2 (PostgreSQL) | Base de datos auto-escalable con capacidad ACU variable (1-32 ACU) |
| Connection pooling | AWS RDS Proxy | Multiplexación inteligente de conexiones para reducir carga en Aurora |
| Capa de aplicación | EC2 Auto Scaling Groups (PHP + Tomcat) | Servidores web y API con escalado automático |
| Balanceo de carga | Application Load Balancer | Distribución de tráfico y health checks |
| Monitorización | CloudWatch + Datadog | Métricas, alarmas y observabilidad |
| Infraestructura como código | Terraform | Gestión reproducible y versionada de toda la infraestructura |
Diagrama de arquitectura
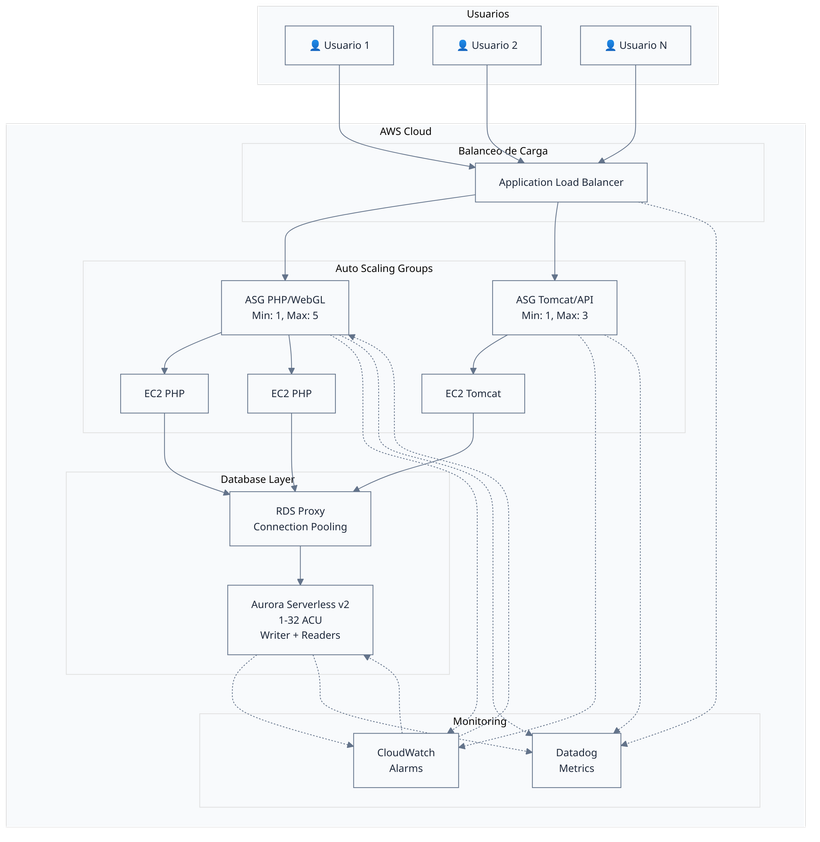
Solución 1: Aurora Serverless v2 con autoscaling híbrido
¿Por qué Aurora Serverless v2 y no RDS PostgreSQL tradicional?
La elección de Aurora Serverless v2 frente a RDS PostgreSQL tradicional fue estratégica y responde directamente al patrón de tráfico en avalancha de Virtway:
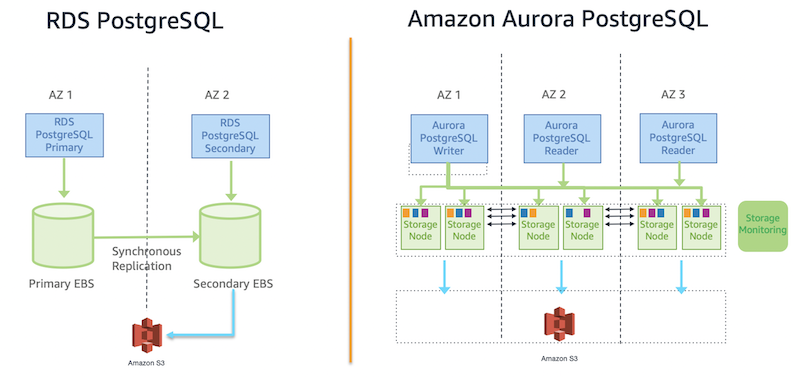
Diferencias arquitectónicas clave: Aurora separa cómputo y almacenamiento, permitiendo escalado independiente de cada capa. RDS tradicional tiene ambas capas acopladas, limitando la flexibilidad de escalado.
Ventajas críticas de Aurora para este caso de uso:
Esta arquitectura permitió implementar el autoscaling híbrido multi-capa que resultó crítico para manejar las avalanchas de tráfico.
Estrategia de autoscaling multi-capa
Implementé un sistema de autoscaling híbrido de 3 capas que combina diferentes estrategias para responder con rapidez excepcional a picos de tráfico:
![]()
![]()
Capa 1: Target Tracking (AWS-Managed): baseline automático
- Métrica: RDSReaderAverageCPUUtilization
- Target: 30% CPU (agresivo para anticipar picos)
- Scale-out cooldown: 30 segundos
- Scale-in cooldown: 2 minutos
- Beneficio: AWS calcula automáticamente acciones óptimas de escalado
Capa 2: Step Scaling (Manual, Agresivo): respuesta a picos extremos
- Alarma CPU >70%: añade 1 reader inmediatamente
- Alarma CPU >85%: añade 2 readers simultáneamente
- Período: 30 segundos (detección ultrarrápida)
- Evaluación: 1 período (acción inmediata sin esperas)
- Beneficio: respuesta agresiva en menos de 1 minuto
Capa 3: Multi-Metric (Proactivo): detección temprana antes de alcanzar capacidad máxima
- Alarma conexiones >280: escala antes del pico histórico de 391 conexiones (70% del máximo observado)
- Alarma latencia >3ms: detecta degradación antes de que usuarios la perciban (75% del pico de 3.8ms)
- Beneficio: escalado preventivo antes de que CPU sea el cuello de botella
Optimización de capacidad vertical
Aumenté significativamente el rango de ACU (Aurora Capacity Units) para permitir escalado vertical más agresivo:
| Métrica | Antes | Después | Mejora |
|---|---|---|---|
| Max ACU por instancia | 20 | 32 | +60% |
| Max capacidad total | 60 ACU | 96 ACU | +60% |
| Umbral CPU efectivo | 40% | 30% | Respuesta anticipada |
Beneficio crítico: el escalado vertical ocurre en segundos, mientras que el horizontal requiere 8 minutos para aprovisionar readers. Esta capacidad adicional mantiene el sistema estable durante la ventana de aprovisionamiento horizontal.
Resultados del autoscaling optimizado
Solución 2: optimización de RDS Proxy y conexiones
Diagnóstico y optimización de conexiones
Una oportunidad clave de optimización identificada fueron las pinned connections: conexiones que RDS Proxy podía multiplexar de forma más eficiente eliminando el estado de sesión (variables temporales, tablas temporales, configuración de sesión).
Investigación profunda realizada:
- Análisis detallado de logs de RDS Proxy identificando patrones de fijación.
- Depuración a bajo nivel de queries que causaban pinning involuntario.
- Revisión exhaustiva del código de aplicación para eliminar uso innecesario de estado de sesión.
- Validación de políticas de clúster Aurora para asegurar enrutamiento correcto de tráfico.
Optimizaciones implementadas:
- Separación estricta de tráfico: queries de lectura exclusivamente al Reader Endpoint, transacciones al Writer.
- Eliminación de estado de sesión: refactorización de código para evitar uso de variables de sesión y tablas temporales.
- Configuración de secuencias Aurora: ajustes en gestión de autoincrementales para alta concurrencia.
- Políticas de clúster optimizadas: definición de reglas para failover correcto y alta disponibilidad.
Resultados de la optimización del proxy
Solución 3: optimización de autoscaling EC2
Arquitectura multi-capa para instancias EC2
Implementé un sistema de autoscaling de 4 capas para los grupos EC2 (PHP/WebGL y Tomcat/API):
Capa 1: Target Tracking - CPU (Safety net)
- Target: 70% CPU utilization
- Respuesta: 2-4 minutos
Capa 2: Target Tracking - ALB Requests (Primary)
- APP Target: 1,000 requests/min per instance
- WAPI Target: 800 requests/min per instance
- Respuesta: 1-3 minutos
Capa 3: Step Scaling (Extreme bursts)
- High Load (1,800 req/min): +2 instancias
- Extreme Load (2,200+ req/min): +3 instancias
- Cooldown: 60 segundos
Capa 4: Scheduled Scaling (Pre-event)
- Scale-up 15-30 min antes del evento
- Capacidad lista cuando usuarios llegan
- Elimina pre-escalado manual
Optimización de grupos de autoscaling
Identifiqué una oportunidad de optimización significativa: separar el servicio Tomcat de las instancias EC2 dedicadas exclusivamente a PHP/WebGL.
Solución implementada:
- Configuración de lógica inteligente en user-data para arrancar Tomcat solo en instancias del ASG correcto.
- Separación clara de responsabilidades entre grupos PHP (frontend/WebGL) y Tomcat (API/backend).
- Configuración dinámica del pool de conexiones Tomcat basada en tamaño del ASG y capacidad de BD.
Beneficios obtenidos:
- Liberación de recursos CPU/memoria en servidores PHP.
- Optimización del número de conexiones a la base de datos.
- Mejor distribución de carga y uso eficiente de recursos.
- Reducción de costes mediante arquitectura optimizada.
Optimizaciones adicionales
Monitorización y observabilidad mejoradas
Infraestructura como código con Terraform
Gestioné toda la infraestructura con Terraform, asegurando:
- Reproducibilidad: infraestructura completamente codificada y versionada.
- Consistencia: misma configuración en development y production.
- Auditoría: historial completo de cambios en control de versiones.
- Documentación: código como documentación viva de la arquitectura.
Resultados e impacto empresarial
Mejoras de rendimiento y disponibilidad
Optimización de costes operativos
Impacto en operaciones
Logros técnicos clave
Lecciones aprendidas
Lo que funcionó excepcionalmente bien:
- Autoscaling híbrido multi-capa: combinación de Target Tracking, Step Scaling y Multi-Metric proporcionó respuesta óptima a diferentes escenarios de tráfico.
- Escalado vertical agresivo: aumento de ACU máximas a 32 proporcionó buffer esencial durante aprovisionamiento horizontal.
- Monitorización proactiva: alarmas basadas en datos históricos reales (connections >280, latency >3ms) permitieron anticipar necesidades de capacidad.
- Infraestructura como código: Terraform aseguró consistencia, reproducibilidad y documentación viva de la arquitectura.
- Separación de responsabilidades: limpieza arquitectónica PHP/Tomcat liberó recursos y simplificó debugging.
Optimizaciones técnicas realizadas:
- Optimización de conexiones: análisis profundo a bajo nivel de logs de RDS Proxy y refactorización de código de aplicación para maximizar multiplexación.
- Tuning de umbrales de alarmas: iteración basada en datos de producción para encontrar puntos óptimos de respuesta anticipada.
- Compensación de tiempos de aprovisionamiento: los 8 minutos para añadir reader se compensan con escalado vertical más agresivo.
- Coordinación de múltiples capas: configuración cuidadosa de cooldowns para asegurar que capas de autoscaling trabajen armoniosamente.
- Validación en producción: validación durante eventos reales con alta carga, con monitorización intensiva y capacidad de ajuste rápido.
Conclusión
Este proyecto de optimización de infraestructura AWS para Virtway Metaverse representa un caso de estudio excepcional sobre cómo diseñar arquitecturas cloud altamente resilientes para patrones de tráfico event-driven con picos extremos. Al combinar Aurora Serverless v2 con autoscaling híbrido multi-capa, optimización profunda de RDS Proxy y optimización completa de autoscaling EC2, desarrollé una plataforma robusta capaz de soportar miles de usuarios simultáneos sin degradación perceptible, con alta disponibilidad y tiempos de respuesta optimizados.
La arquitectura resultante establece una base sólida para crecimiento futuro. El sistema ahora escala automáticamente anticipando la demanda, mantiene costes bajo control mediante scale-in agresivo y proporciona visibilidad operacional completa para análisis y optimización continua.
Conclusiones clave para proyectos similares
- Arquitecturas event-driven requieren autoscaling multi-capa que combine respuesta inmediata (Step Scaling), gestión automática (Target Tracking) y anticipación proactiva (Multi-Metric).
- RDS Proxy requiere optimización cuidadosa - eliminar pinned connections maximiza los beneficios de multiplexación.
- Escalado vertical como buffer para escalado horizontal: ACU variables de Aurora Serverless v2 compensan los 8 minutos de aprovisionamiento de readers.
- Monitorización multi-dimensional es esencial: CPU solo no es suficiente, necesitas conexiones, latencia y múltiples métricas para anticipar necesidades de capacidad.
- Separación clara de responsabilidades: arquitectura limpia PHP/Tomcat facilita debugging, optimización y escalado independiente.
¿Necesitas optimizar tu infraestructura AWS?
Si tu aplicación enfrenta desafíos similares:
- Picos de tráfico extremos que requieren infraestructura altamente escalable.
- Optimización de escalabilidad con bases de datos bajo alta carga.
- Disponibilidad durante eventos o momentos de máxima demanda.
- Optimización de costes de AWS manteniendo alto rendimiento.
- Modernización de arquitectura para alta disponibilidad y escalabilidad.
Como arquitecto cloud AWS con 20+ años de experiencia, puedo ayudarte a diseñar e implementar soluciones escalables que soporten tus cargas de trabajo más exigentes manteniendo costes bajo control.
Especializado en Aurora Serverless v2, autoscaling inteligente, optimización de RDS Proxy y arquitecturas event-driven de alta disponibilidad.
Ponte en contacto →

Sobre el autor
Daniel López Azaña
Emprendedor tecnológico y arquitecto cloud con más de 20 años de experiencia transformando infraestructuras y automatizando procesos. Especialista en integración de IA/LLM, desarrollo con Rust y Python, y arquitectura AWS & GCP. Mente inquieta, generador de ideas y apasionado por la innovación tecnológica y la IA.
Proyectos relacionados
Optimalway: infraestructura AWS y optimización
Infraestructura AWS escalable con autoescalado para PHP y Java, optimización MongoDB y análisis rendimiento Apache/PHP-FPM/Tomcat. Partner cloud de confianza.

Consultoría de seguridad e infraestructura AWS para plataforma web
Auditoría de seguridad completa y optimización de infraestructura AWS para plataforma de aplicaciones web, detectando y resolviendo vulnerabilidades críticas, implementando sistemas de monitorización y modernizando el stack tecnológico.

11 años de colaboración AWS - Administración completa de sistemas para empresa de hosting
Gestión de infraestructura AWS durante más de una década con 99.9% de disponibilidad mediante monitorización proactiva, respuesta a crisis, optimización de costes y transición empresarial profesional. Una relación construida sobre confianza, soluciones pragmáticas y evolución continua.
Comentarios
Enviar comentario