Las plataformas de préstamos en el sector fintech enfrentan desafíos técnicos únicos: arquitectura multi-tenant donde cada lender opera en completo aislamiento, requisitos complejos de cumplimiento normativo y la necesidad de despliegues rápidos y seguros sin interrupción del servicio. Evolucionar desde una infraestructura monolítica hacia una arquitectura cloud profesional y escalable requiere planificación cuidadosa y profunda experiencia en DevOps.

Proporcioné servicios integrales de consultoría DevOps y arquitectura cloud para una plataforma confidencial fintech de préstamos durante 2018 (marzo-septiembre). El proyecto implicó diseñar e implementar una transformación completa de infraestructura AWS: migración a arquitectura containerizada con ECS Fargate, implementación de pipelines CI/CD automatizados con GitLab, segregación de red con VPCs aisladas y despliegue de mejores prácticas de monitorización y seguridad siguiendo principios DevSecOps.
Contexto del proyecto y requisitos técnicos
El cliente operaba una plataforma de préstamos conectando múltiples lenders (entidades financieras) con solicitantes. Cada lender requería aislamiento completo de entorno con instancias separadas de demo, staging y producción.
Situación técnica inicial:
- Modelo de despliegue monolítico con procesos manuales.
- Segregación limitada de entornos creando riesgos de cumplimiento.
- Ciclos de despliegue lentos impactando el time-to-market.
- Conflictos de direccionamiento IP (rangos 172.x.x.x) complicando la gestión de red.
- Gestión manual de certificados de seguridad.
- Capacidades limitadas de monitorización y alertas.
Objetivos del proyecto:
- Diseñar e implementar arquitectura AWS multi-tenant profesional.
- Automatizar el aprovisionamiento de infraestructura y despliegue de aplicaciones.
- Asegurar aislamiento completo de entornos y tenants para cumplimiento normativo.
- Reducir tiempo de despliegue de horas a minutos.
- Implementar seguridad y monitorización integrales.
- Habilitar escalado rápido para múltiples lenders sin cuellos de botella en infraestructura.
Diseño e implementación de arquitectura
Stack containerizado de tres capas
Diseñé una arquitectura moderna de tres capas optimizada para despliegues containerizados:
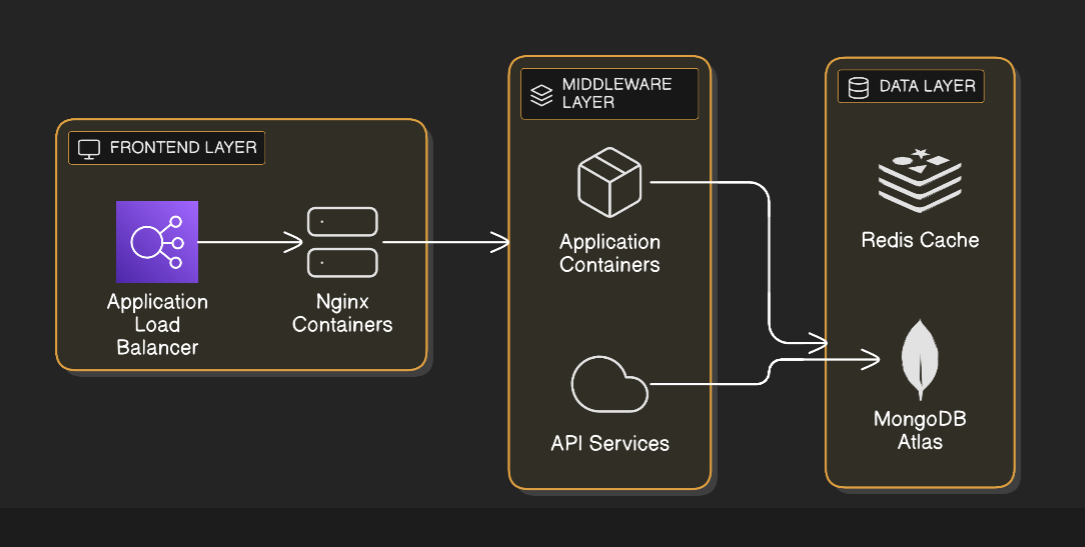
Componentes por capa:
- Frontend: contenedores Nginx actuando como reverse proxy manejando terminación SSL y enrutamiento de peticiones.
- Middleware: servidores de aplicación y servicios API ejecutándose en contenedores aislados.
- Datos: clusters MongoDB Atlas con control de acceso basado en roles y Redis para caché.
Arquitectura de red y diseño VPC
Normalización del direccionamiento IP:
- Migré desde rangos 172.x.x.x conflictivos a direccionamiento estandarizado 10.0.x.x.
- Eliminé conflictos IP con redes corporativas y servicios de terceros.
- Simplifiqué el enrutamiento y las reglas de security groups.
Estrategia de segregación VPC:
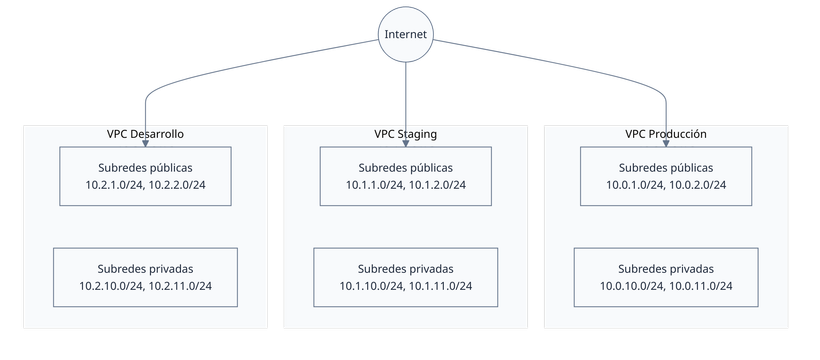
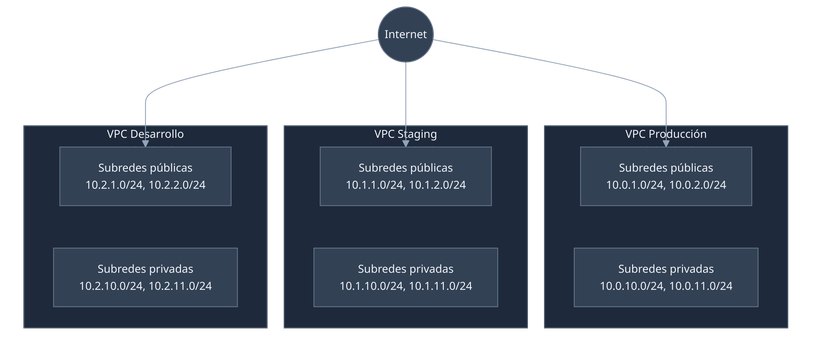
Implementación de seguridad:
- Aislamiento completo de red entre entornos de producción, staging y desarrollo.
- Subredes públicas solo para load balancers y NAT gateways.
- Subredes privadas para todas las cargas de trabajo de aplicación y base de datos.
- Security groups implementando patrones de acceso de mínimo privilegio.
- VPC peering deshabilitado para prevenir acceso entre entornos.
Estructura multi-tenant de entornos
Cada lender recibió tres entornos completos:
Entorno demo
Demostraciones comerciales y evaluaciones de prospectos. Datos aislados, escenarios preconfigurados y autenticación simplificada para presentaciones de ventas.
Entorno staging
Pruebas pre-producción con configuración equivalente a producción. Pruebas de integración completas, validación UAT y pruebas de rendimiento antes del despliegue a producción.
Entorno producción
Sistema productivo en vivo sirviendo usuarios reales y procesando transacciones reales. Configuración de alta disponibilidad, backups automatizados y monitorización integral.
Estructura de dominios implementada:
- Dominios wildcard para la plataforma principal.
- Dominios separados para instancias white-label.
- Aprovisionamiento automatizado de certificados SSL vía AWS Certificate Manager.
- Gestión DNS integrada con pipelines de despliegue.

Orquestación de contenedores: migración a ECS Fargate
Prueba de concepto e implementación en producción
Lideré la migración completa desde gestión tradicional de contenedores basada en EC2 hacia orquestación serverless de contenedores con AWS Fargate.
Fases de migración:
- Desarrollo de POC: construí prueba de concepto demostrando viabilidad de Fargate para la carga de trabajo.
- Automatización con CloudFormation: desarrollé templates de infraestructura como código para despliegues repetibles.
- Activación de cluster productivo: desplegué cluster ECS de producción con tipo de lanzamiento Fargate.
- Migración de aplicaciones: migración sistemática de servicios desde Rancher/EC2 a Fargate.
Ventajas de Fargate conseguidas:
- Cero overhead de gestión de servidores (sin parcheo, escalado ni monitorización de EC2).
- Modelo de precios pay-per-use reduciendo costos durante períodos de bajo tráfico.
- Alta disponibilidad automática a través de múltiples availability zones.
- Seguridad simplificada con integración VPC y roles IAM para tareas.
- Despliegues más rápidos con infraestructura abstraída.
Gestión y optimización de contenedores
Definiciones de tareas y gestión del ciclo de vida:
- Implementé políticas automatizadas de ciclo de vida para ECR (Elastic Container Registry).
- Configuré reglas de retención para limpiar versiones antiguas de task definitions.
- Reduje costos de almacenamiento ECR eliminando imágenes no usadas automáticamente.
- Mantuve registro de auditoría de todas las versiones desplegadas para cumplimiento.
Optimización de recursos EC2 con Rancher:
- Identifiqué instancias de gestión Rancher sobre-aprovisionadas.
- Ajusté el tamaño de instancias de m5.xlarge a m5.large según patrones de uso reales.
- Reduje costos de infraestructura de gestión en un 35%.
- Mantuve Rancher para cargas de trabajo legacy durante período de transición.
Implementación de pipelines CI/CD
Integración GitLab CI/CD
Implementé automatización integral CI/CD usando pipelines GitLab integrados con servicios AWS.
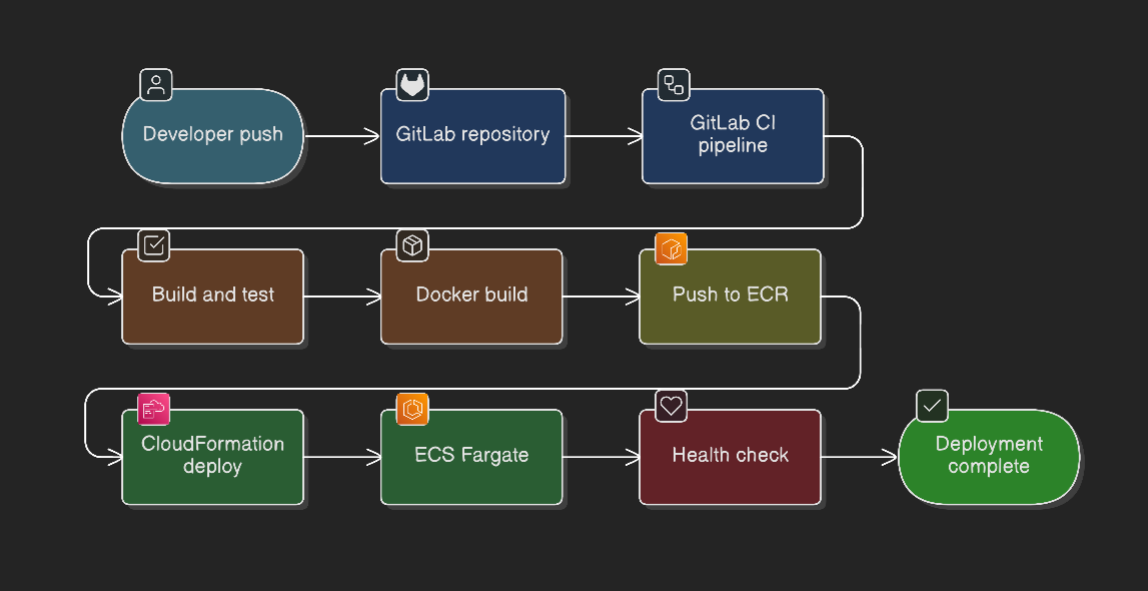
Etapas del pipeline implementadas:
- Etapa source: push a Git dispara pipeline automáticamente.
- Etapa build: compilación de aplicación y ejecución de pruebas unitarias.
- Docker build: creación de imagen de contenedor con optimización.
- Push a ECR: subida segura a registro de contenedores con escaneo de vulnerabilidades.
- Despliegue infraestructura: actualizaciones de stack CloudFormation para cambios de infraestructura.
- Despliegue aplicación: actualizaciones de task definition ECS y despliegue de servicio.
- Health checks: verificación automatizada del éxito del despliegue.
- Capacidad de rollback: rollback automático ante fallos en health checks.
Infraestructura de GitLab Runners
Decisiones de arquitectura de runners:
Evalué e implementé infraestructura personalizada de GitLab Runners en AWS en lugar de usar shared runners.
Runners personalizados en AWS:
- Desplegué instancias EC2 dedicadas como GitLab Runners.
- Configuré grupos de runners con auto-escalado para ejecución paralela de pipelines.
- Implementé Docker-in-Docker para entornos de build aislados.
- Reduje tiempo de ejecución de pipelines en un 60% versus shared runners.
- Eliminé retrasos por cola durante períodos de alta demanda.
- Mantuve control completo sobre entorno de build y dependencias.
Análisis costo-beneficio:
- Runners personalizados proporcionaron builds más rápidos a pesar de costos de infraestructura.
- Eliminé rendimiento impredecible de shared runners.
- Mejoré productividad de desarrolladores con ciclos de feedback más rápidos.
- Justifiqué costo mediante reducción de tiempo de espera de desarrolladores.
POC de AWS CodePipeline
Desarrollé prueba de concepto usando CodePipeline y CodeBuild nativos de AWS como alternativa a GitLab CI.
Resultados del POC:
- Validé CI/CD nativo de AWS como alternativa viable para cargas de trabajo específicas.
- Identifiqué mejor integración con servicios AWS (CloudFormation, ECS).
- Documenté comparativa de costos entre GitLab y soluciones nativas de AWS.
- Recomendé enfoque híbrido: GitLab para pipelines de aplicación, CodePipeline para infraestructura.
Implementación de seguridad
Gestión de certificados SSL/TLS
Integración AWS Certificate Manager:
- Aprovisionamiento automatizado de certificados para todos los load balancers.
- Certificados wildcard para dominios de plataforma y white-label.
- Renovación automática de certificados eliminando procesos manuales.
- Integración con Application Load Balancers para HTTPS automático.
Implementación Let’s Encrypt:
- Desplegué Let’s Encrypt para servicios sin load balancer.
- Renovación automatizada de certificados con certbot.
- Creé scripts de automatización personalizados para despliegue de certificados multi-servicio.
Hardening de seguridad
Imposición de HTTPS:
- Configuré redirección de HTTP a HTTPS en todos los dominios.
- Implementé cabeceras HSTS (HTTP Strict Transport Security).
- Deshabilité protocolos y cifrados inseguros en load balancers.
- Validé configuración SSL logrando calificación A+ en SSL Labs.
Prácticas DevSecOps:
- Revisé e implementé mejores prácticas de seguridad AWS.
- Configuré roles IAM siguiendo principio de mínimo privilegio.
- Creé usuarios IAM dedicados para acceso API con permisos mínimos.
- Habilité CloudTrail para logging de auditoría de todas las llamadas API.
- Implementé reglas de security group restringiendo tráfico solo a puertos requeridos.
- Configuré VPC flow logs para análisis de tráfico de red.
Infraestructura de base de datos: MongoDB Atlas
![]()
Gestión de clusters y seguridad
Configuración MongoDB Atlas:
- Recreé clusters Atlas alineados con nuevo esquema de direccionamiento IP.
- Configuré VPC peering entre VPCs de AWS y clusters Atlas.
- Implementé restricciones de whitelist IP para seguridad a nivel de red.
Control de acceso y permisos:
- Diseñé control de acceso basado en roles (RBAC) granular para usuarios de base de datos.
- Creé usuarios de base de datos separados por entorno (demo, staging, prod).
- Implementé usuarios solo-lectura para reporting y analytics.
- Configuré usuarios específicos de aplicación con permisos mínimos requeridos.
- Habilité logging de auditoría Atlas para requisitos de cumplimiento.
Optimización de rendimiento:
- Configuré tiers de cluster apropiados para cada entorno.
- Implementé mejores prácticas de connection pooling en código de aplicación.
- Configuré monitorización de rendimiento MongoDB Atlas y alertas de consultas lentas.
- Configuré backups automatizados con recuperación point-in-time.
Monitorización y operaciones
Implementación CloudWatch
Configuración integral de monitorización:
- Configuré CloudWatch Logs para logging centralizado de aplicaciones.
- Creé log groups por servicio para gestión organizada de logs.
- Implementé políticas de retención de logs para optimización de costos.
- Configuré CloudWatch Metrics para monitorización de infraestructura y aplicación.
Alertas y gestión de eventos:
- Creé CloudWatch Alarms para métricas críticas de infraestructura.
- Configuré topics SNS para enrutamiento de alertas a múltiples canales.
- Implementé escalado de alertas para issues no resueltos.
- Integré con PagerDuty para gestión de incidentes on-call.
Métricas clave monitorizadas:
- Salud del servicio ECS y fallos de tareas.
- Salud de targets de load balancer y tiempos de respuesta.
- Utilización de connection pools de base de datos.
- Fechas de expiración de certificados (para Let’s Encrypt).
- Tasas de éxito de ejecución de pipelines y duraciones.
Optimización de despliegues
Desafíos iniciales identificados:
- Despliegues de contenedores tomando 15-20 minutos debido a descargas de dependencias.
- Limitaciones de ancho de banda de red durante instalación de paquetes npm/pip.
- Despliegue secuencial causando ventanas de downtime extendidas.
- Imágenes Docker grandes (más de 1.5GB) causando transferencias lentas a ECR.
Optimizaciones implementadas:
- Optimicé imágenes Docker con multi-stage builds reduciendo tamaño de imagen en 60%.
- Implementé layer caching para builds subsecuentes más rápidos.
- Pre-descargué dependencias comunes en imágenes base.
- Configuré despliegues paralelos de servicios donde las dependencias lo permitían.
- Reduje tiempo promedio de despliegue a 8-10 minutos (desde 15-20 minutos iniciales).
Optimización de arranque Fargate:
- Investigué y resolví tiempos lentos de arranque de contenedores en Fargate.
- Optimicé asignación de recursos de task definition (CPU/memoria).
- Implementé ajuste de health checks para evitar terminación prematura de tareas.
- Configuré deregistration delay en load balancers para shutdowns elegantes.
Evaluación e implementación de plataforma CRM

Como flujo de trabajo paralelo, evalué y desplegué sistemas CRM para uso interno y gestión de lenders.
Personalización SuiteCRM
Implementación:
- Desplegué instancias dedicadas SuiteCRM para uso interno y lenders.
- Personalicé look and feel con directrices de branding del cliente.
- Traduje interfaz al español para el mercado local.
- Configuré módulos para flujos de trabajo específicos de préstamos.
- Integré con APIs de plataforma para sincronización de datos.
Evaluación VtigerCRM
Análisis comparativo:
- Desplegué instancia VtigerCRM para comparación de funcionalidades.
- Evalué costos de licenciamiento versus SuiteCRM.
- Comparé capacidades de personalización y ecosistemas de extensiones.
- Documenté recomendaciones para estrategia CRM a largo plazo.
Gestión de proyecto y documentación
Metodología ágil
Seguimiento de proyecto con Jira:
- Organicé trabajo en Epics: “Infraestructura y DevOps” e “Implementación CRM”.
- Mantuve planificación y ejecución de sprints con ciclos de sprint de 2 semanas.
- Rastreé velocidad y usé burndown charts para monitorización de progreso.
- Conduje retrospectivas regulares para mejora continua.
Documentación en Confluence
Documentación técnica creada:
- Diagramas completos de arquitectura con integración Lucidchart.
- Documentación de topología de red con esquemas de direccionamiento IP.
- Runbooks de despliegue para cada servicio.
- Guías de troubleshooting para issues comunes.
- Roadmap DevOps proponiendo mejoras futuras.
Documentación operacional:
- Procedimientos de respuesta a incidentes.
- Rotación on-call y procedimientos de escalado.
- Procesos de gestión de cambios.
- Procedimientos de disaster recovery y backup.
Cronología del proyecto e hitos
Fase 1: fundamentos (marzo-mayo 2018)
- Diseño de arquitectura inicial y propuesta.
- Ejecución de NDA y onboarding de cliente.
- Diseño de VPC y definición de arquitectura de red.
- Desarrollo de templates de infraestructura como código.
- Evaluación inicial de sistema CRM y despliegue.
Fase 2: implementación (junio-julio 2018)
- Desarrollo y validación de POC ECS Fargate.
- Implementación de pipeline GitLab CI/CD.
- Configuración de automatización de certificados SSL.
- Migración de cluster MongoDB Atlas.
- Activación de cluster productivo y primeros despliegues a producción.
Hito julio: estabilización del proyecto completada con todos los servicios core ejecutándose en producción en Fargate.
Fase 3: optimización (agosto-septiembre 2018)
- Optimización de rendimiento de pipelines de despliegue.
- Optimización de costos mediante right-sizing y políticas de ciclo de vida.
- Completado de documentación en Confluence.
- Resolución de incidentes y mantenimiento.
- Planificación de prioridades Q4: monitorización avanzada, desacople final de redes, auditoría de seguridad.
Resultados e impacto empresarial
Mejoras de infraestructura
Velocidad de despliegue:
- Reduje tiempo de despliegue de 2-3 horas (manual) a 8-10 minutos (automatizado).
- Habilité múltiples despliegues diarios sin disrupción.
- Reduje time-to-market para onboarding de nuevos lenders en 70%.
Eficiencia operacional:
- Eliminé pasos manuales de despliegue reduciendo error humano en 90%.
- Reduje overhead de gestión de infraestructura en 60%.
- Habilité despliegues self-service para equipos de desarrollo.
- Reduje mean time to recovery (MTTR) de 45 minutos a 12 minutos.
Optimización de costos:
- Reduje overhead operacional en 60% manteniendo costos de infraestructura similares.
- El modelo pay-per-use de Fargate eliminó capacidad ociosa durante períodos de bajo tráfico.
- Optimicé costos de base de datos en 30% mediante sizing apropiado de clusters Atlas y connection pooling.
- Trade-off: costos de cómputo ligeramente superiores compensados por reducción dramática de carga operacional.
Seguridad y cumplimiento
Mejoras de postura de seguridad:
- Logré aislamiento completo de entornos para requisitos de cumplimiento.
- Implementé logging de auditoría integral para requisitos regulatorios.
- Automaticé gestión de certificados de seguridad eliminando riesgos de expiración.
- Establecí mejores prácticas de seguridad siguiendo principios DevSecOps.
Capacidades de plataforma
Logros de escalabilidad:
- Habilité onboarding rápido de nuevos lenders sin cambios de infraestructura.
- Soporté 3 entornos completos por lender (demo, staging, prod).
- Establecí fundación para escalado horizontal futuro conforme crece la plataforma.
Insights técnicos
Beneficios y trade-offs de ECS Fargate
Aprendizajes clave:
- Fortalezas de Fargate: excelente para cargas de trabajo con patrones de tráfico variable, elimina gestión de servidores, modelo de seguridad sólido con integración IAM.
- Requisitos de optimización: optimización de arranque de contenedores crítica para servicios cara al usuario, ajuste de health checks esencial para estabilidad.
- Consideraciones de costo: más cost-effective que EC2 para cargas de trabajo variables, menos económico para servicios con alta utilización consistente.
Lecciones de arquitectura multi-tenant
Factores críticos de éxito:
- Aislamiento completo: segregación a nivel de red no es negociable para cumplimiento.
- Necesidad de automatización: gestión manual de múltiples entornos imposible a escala.
- Gestión de configuración: Parameter Store y Secrets Manager esenciales para configuración multi-tenant segura.
- Complejidad de monitorización: métricas y alertas por tenant requeridas para aislamiento apropiado.
Mejores prácticas de pipelines CI/CD
Lo que funcionó bien:
- GitLab Runners personalizados en AWS proporcionaron rendimiento predecible.
- Docker layer caching redujo dramáticamente tiempos de build.
- CloudFormation para infraestructura como código habilitó despliegues consistentes.
- Automatización de health checks previno que despliegues malos alcanzaran producción.
Áreas de mejora:
- Optimización inicial de descarga de dependencias debió hacerse antes.
- Despliegues paralelos podrían haberse implementado antes.
- Pruebas de integración en pipelines necesitaban más inversión.
Tecnologías y herramientas
Conclusión
Este proyecto integral de consultoría DevOps transformó exitosamente una plataforma fintech de préstamos manual y monolítica en una infraestructura AWS moderna, automatizada y multi-tenant. La implementación de ECS Fargate, pipelines GitLab CI/CD, segregación apropiada de red y prácticas integrales de seguridad establecieron una fundación sólida para el crecimiento continuo de la plataforma.
El proyecto demostró el valor de la infraestructura como código, pipelines de despliegue automatizados y mejores prácticas DevSecOps en entornos de servicios financieros altamente regulados. Al habilitar despliegues rápidos y seguros y aislamiento completo de entornos, la plataforma ganó las capacidades técnicas necesarias para escalar su negocio a múltiples lenders mientras mantiene requisitos de cumplimiento.
El proyecto de 6 meses (marzo-septiembre 2018) entregó una infraestructura production-ready soportando múltiples tenants a través de entornos demo, staging y producción, con monitorización integral, seguridad y documentación operacional habilitando al equipo interno del cliente para mantener y evolucionar el sistema independientemente.
¿Necesitas transformación DevOps para tu plataforma fintech?
Si tu organización enfrenta desafíos similares:
- Procesos de despliegue manuales causando retrasos y errores de despliegue en producción.
- Falta de aislamiento de entornos para aplicaciones fintech multi-tenant.
- Sin automatización CI/CD ralentizando velocidad de desarrollo y time-to-market.
- Infraestructura monolítica haciendo el escalado y mantenimiento cada vez más difícil.
- Requisitos de cumplimiento (PCI DSS, SOC 2) sin controles de seguridad apropiados.
Como consultor DevOps con 20+ años de experiencia en infraestructura y expertise en fintech, puedo ayudarte a modernizar tu infraestructura con contenedorización, automatización CI/CD, Infrastructure as Code, aislamiento multi-tenant y prácticas de seguridad integrales.
Especializado en AWS ECS Fargate, GitLab CI/CD, Terraform, Docker y DevSecOps para servicios financieros regulados.
Ponte en contacto →

Sobre el autor
Daniel López Azaña
Emprendedor tecnológico y arquitecto cloud con más de 20 años de experiencia transformando infraestructuras y automatizando procesos. Especialista en integración de IA/LLM, desarrollo con Rust y Python, y arquitectura AWS & GCP. Mente inquieta, generador de ideas y apasionado por la innovación tecnológica y la IA.
Proyectos relacionados
Domestika: transformación de infraestructura DevOps y cloud
Lideré la modernización integral de la infraestructura cloud para una plataforma de aprendizaje creativo en rápido crecimiento, implementando arquitectura AWS multi-región y automatización DevOps completa que respaldaron el crecimiento de la empresa de 20 empleados a unicornio.

Consultoría de seguridad e infraestructura AWS para plataforma web
Auditoría de seguridad completa y optimización de infraestructura AWS para plataforma de aplicaciones web, detectando y resolviendo vulnerabilidades críticas, implementando sistemas de monitorización y modernizando el stack tecnológico.

Optimización de infraestructura AWS para Virtway Metaverse - Aurora Serverless v2 y autoscaling inteligente
Arquitectura AWS altamente escalable diseñada para soportar eventos virtuales con picos de tráfico extremos en Virtway Metaverse. Implementación de Aurora Serverless v2 con autoscaling híbrido multi-capa, RDS Proxy optimizado y estrategias avanzadas de escalado que redujeron la latencia y costes mientras garantizaban disponibilidad durante avalanchas de conexiones simultáneas.
Comentarios
Enviar comentario