Descripción del proyecto
Las organizaciones que operan aplicaciones web distribuidas globalmente enfrentan desafíos críticos para garantizar disponibilidad y rendimiento consistentes para usuarios en todo el mundo. Como arquitecto cloud AWS independiente, he diseñado e implementado soluciones integrales de balanceo de carga global y alta disponibilidad para múltiples clientes de diferentes industrias, cada uno operando aplicaciones web y servicios críticos para el negocio con bases de usuarios internacionales.

Estas organizaciones típicamente enfrentaban limitaciones de infraestructura similares. Sus servicios se concentraban en zonas de disponibilidad únicas, creando puntos únicos de fallo que exponían sus negocios a riesgos significativos de interrupción del servicio. Además, los usuarios en diferentes regiones geográficas experimentaban latencias inconsistentes, afectando negativamente la experiencia de usuario y la eficiencia operacional.
Para cada cliente, desarrollé transformaciones arquitectónicas completas aprovechando AWS Global Accelerator, Application Load Balancers y patrones de despliegue multi-región para proporcionar disponibilidad, resiliencia y optimización de rendimiento de nivel empresarial, adaptadas a sus requisitos específicos y patrones de tráfico.
El desafío: superando la latencia y la fragilidad
El estado inicial de la infraestructura para estos clientes era precario. Ejecutar todos los servicios dentro de una única zona de disponibilidad creaba un punto de fallo crítico; una interrupción en ese centro de datos específico podía dejar fuera de línea todo el negocio. Esta falta de redundancia significaba que cualquier mantenimiento o problema inesperado requería intervención manual y a menudo resultaba en caídas del servicio.
Más allá de la disponibilidad, la experiencia del usuario global era inconsistente. Los usuarios fuera de la región principal sufrían latencias variables ya que su tráfico atravesaba internet público a través de múltiples saltos, provocando pérdida de paquetes y “jitter”. Gestionar este entorno era operacionalmente complejo. Un requisito crítico de negocio por parte de los clientes corporativos era la capacidad de incluir direcciones IP específicas en listas blancas (whitelisting) para el acceso a través de sus firewalls. La arquitectura de IPs dinámicas existente hacía esto imposible, creando fricción durante la integración de nuevos clientes. Además, sin una gestión centralizada de certificados SSL/TLS, el cumplimiento de las normativas de seguridad era difícil de mantener. La arquitectura necesitaba evolucionar de un modelo frágil de servidor único a una plataforma global robusta y auto-reparable.
Arquitectura global y flujo de tráfico
Para abordar estos desafíos, diseñé una solución de múltiples capas que optimiza el tráfico desde el borde hasta la aplicación. La arquitectura comienza con AWS Global Accelerator, que sirve como punto de entrada para todo el tráfico de usuarios.
¿Por qué Global Accelerator en lugar de CloudFront?
Aunque CloudFront es el estándar para la entrega de contenido, no era la opción adecuada para esta carga de trabajo específica. La plataforma dependía en gran medida del contenido dinámico, cuyo cacheo ya estaba gestionado por una capa personalizada de Varnish, ya que esta implementaba una lógica compleja y características avanzadas que superaban las capacidades estándar de CloudFront. Más importante aún, el ecosistema de aplicaciones incluía no solo servicios web, sino también servicios auxiliares basados en TCP (SmartFoxServer) y protocolos UDP para VoIP, que requerían soporte de protocolos más allá del estándar HTTP/HTTPS. Finalmente, el requisito estricto de direcciones IP Anycast estáticas para el whitelisting en los firewalls de los clientes convirtió a Global Accelerator en la elección arquitectónica definitiva.
Al proporcionar dos direcciones IP Anycast estáticas, simplificamos significativamente las configuraciones de firewall de los clientes, ya que estas IPs permanecen constantes independientemente de los cambios en la infraestructura subyacente. Esta capa también incluye protección AWS Shield por defecto, salvaguardando la aplicación contra ataques DDoS comunes de capa de red y transporte sin configuración adicional.
El tráfico entra en la red global de AWS en la ubicación de borde más cercana al usuario, evitando el congestionado internet público. Este enrutamiento optimizado reduce inmediatamente la latencia y la pérdida de paquetes. Desde allí, el tráfico se dirige a la región apropiada (Irlanda o Frankfurt) basándose en la salud y la proximidad.
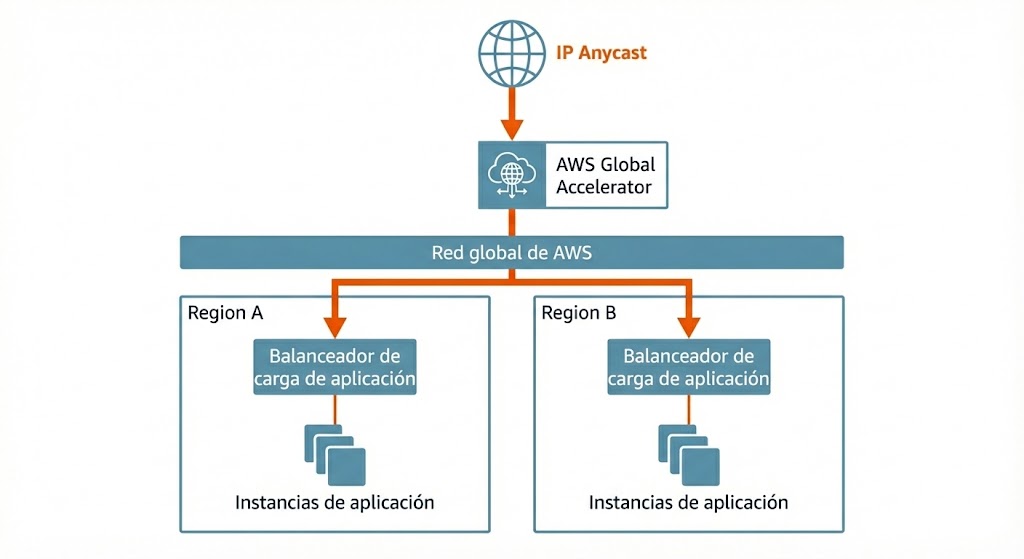
Dentro de la VPC, los Application Load Balancers (ALB) y Network Load Balancers (NLB) manejan la distribución del tráfico a través de múltiples zonas de disponibilidad (AZs). Los ALBs gestionan el tráfico HTTP/HTTPS con reglas de enrutamiento inteligentes basadas en encabezados de host y rutas, mientras gestionan centralmente los certificados SSL/TLS a través de AWS ACM. Esta configuración asegura que el cifrado se maneje de manera eficiente y que el tráfico se enrute de forma segura a los grupos de destino de la aplicación correctos.
Resiliencia de red
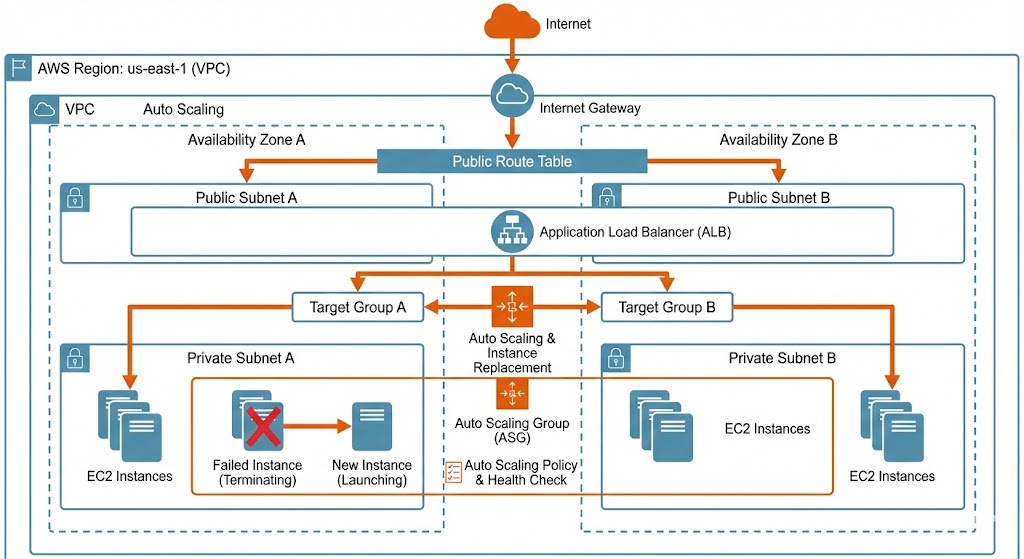
La red subyacente se rediseñó completamente para soportar esta alta disponibilidad. Los recursos se distribuyeron a través de tres zonas de disponibilidad (AZ-1a, AZ-1b, AZ-1c) en la región principal, con el descubrimiento de servicios interno gestionado a través de zonas privadas alojadas en Amazon Route 53. Este despliegue Multi-AZ asegura que incluso si un centro de datos entero deja de funcionar, los balanceadores de carga redirigen automáticamente el tráfico a instancias saludables en las zonas restantes sin interrupción del servicio.
Para servicios críticos, un despliegue secundario en la región de Frankfurt proporciona recuperación ante desastres entre regiones. Esta configuración activo-pasivo garantiza que los datos y servicios permanezcan disponibles incluso en el improbable caso de una interrupción regional completa.
Resiliencia automatizada y gestión de infraestructura
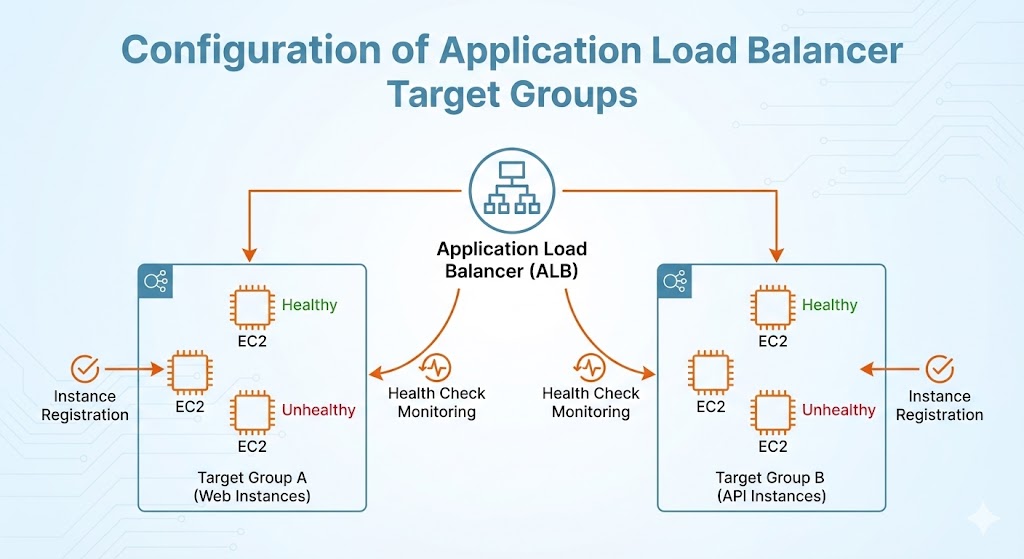
Un componente clave de esta arquitectura es su capacidad para “respirar” y adaptarse a condiciones cambiantes sin intervención humana. Esta resiliencia se logra a través de Auto Scaling Groups integrados con los health checks del Application Load Balancer y la monitorización de Amazon CloudWatch.
En lugar de mantener un conjunto estático de servidores, el sistema aprovecha las métricas de CloudWatch para monitorizar la salud y el rendimiento de cada instancia. Si un servidor falla un health check, ya sea debido a un error de software o un problema de hardware, el grupo de autoescalado lo elimina inmediatamente de la rotación y lanza un reemplazo. Esta capacidad de auto-reparación asegura que la aplicación siempre mantenga su capacidad requerida.
La estrategia de imagen maestra “web0”
Para garantizar la consistencia en todas las instancias creadas dinámicamente, implementé un flujo de trabajo de gestión de configuración riguroso utilizando una estrategia de “Imagen Maestra” (Golden Image). Este enfoque basado en grupos de autoescalado y AMIs personalizadas se eligió específicamente porque la mayoría de las aplicaciones existentes de estos clientes no estaban diseñadas para el uso de contenedores. Al aprovechar las Launch Templates y AMIs inmutables, logramos una escalabilidad moderna y automatizada sin la complejidad y el riesgo de refactorizar pilas de aplicaciones completas para Docker o Kubernetes.
Una instancia de staging dedicada, conocida como web0, sirve como plantilla maestra para todo el grupo de servidores. Esta instancia opera fuera de los balanceadores de carga de producción y se utiliza exclusivamente para probar cambios a nivel de sistema, como parches de seguridad o nuevos despliegues de aplicaciones. Una vez que una configuración se valida en web0, un proceso automatizado genera una nueva Amazon Machine Image (AMI).
Esta nueva AMI se referencia entonces en las Launch Templates utilizadas por los grupos de autoescalado. Para desplegar una actualización, simplemente activamos una actualización de instancias. Los grupos de autoescalado reemplazan gradualmente las instancias antiguas por nuevas que ejecutan la AMI actualizada, asegurando un proceso de despliegue sin tiempo de inactividad. Este flujo de trabajo garantiza que cada servidor en producción sea idéntico, eliminando la desviación de configuración y haciendo que la infraestructura sea inmutable y predecible.
Resultados e impacto
La transformación de esta infraestructura entregó valor comercial inmediato y medible. Al pasar a una arquitectura Multi-AZ con Global Accelerator, logramos un SLA de tiempo de actividad del 99.99%, eliminando efectivamente las interrupciones del servicio causadas por fallos de infraestructura. Las capacidades de auto-reparación significaron que el equipo de operaciones ya no tenía que despertarse por la noche para reiniciar servidores bloqueados; el sistema se reparaba a sí mismo.
Las mejoras de rendimiento fueron igualmente impresionantes. Los usuarios globales experimentaron hasta una reducción del 60% en la latencia gracias al enrutamiento optimizado a través de la red troncal de AWS. La introducción de IPs Anycast estáticas resolvió los dolores de cabeza operativos para clientes corporativos con firewalls estrictos, mientras que la gestión centralizada de certificados mejoró la postura general de seguridad.
En última instancia, este proyecto convirtió una infraestructura frágil y manual en una plataforma resiliente, automatizada y escalable globalmente, lista para el crecimiento futuro.
¿Necesitas una arquitectura global de alta disponibilidad con failover automático?
Si tu organización enfrenta desafíos similares:
- Infraestructura de región única vulnerable a interrupciones completas por fallos regionales de AWS.
- Alta latencia para usuarios globales accediendo a tu aplicación desde ubicaciones distantes.
- Restricciones de firewall corporativo requiriendo direcciones IP estáticas para whitelisting.
- Recuperación manual de servidores durante fallos causando downtime extendido y overhead operacional.
- Sin protección DDoS dejando tu aplicación vulnerable a ataques volumétricos.
Como arquitecto cloud AWS con 20+ años de experiencia en infraestructura, puedo ayudarte a diseñar e implementar arquitecturas multi-región con AWS Global Accelerator, failover automático, Auto Scaling Groups auto-reparables y protección DDoS completa con AWS Shield.
Especializado en implementación de Global Accelerator, arquitecturas multi-AZ, Application Load Balancers y despliegues automatizados sin downtime.
Ponte en contacto →

Sobre el autor
Daniel López Azaña
Emprendedor tecnológico y arquitecto cloud con más de 20 años de experiencia transformando infraestructuras y automatizando procesos. Especialista en integración de IA/LLM, desarrollo con Rust y Python, y arquitectura AWS & GCP. Mente inquieta, generador de ideas y apasionado por la innovación tecnológica y la IA.
Proyectos relacionados
Arquitectura de seguridad de red multinivel en AWS con VPC, NAT Gateway y protección perimetral
Diseño e implementación de arquitectura de seguridad AWS empresarial con VPC multi-nivel, separación de subredes públicas y privadas, NAT Gateway para tráfico saliente controlado, despliegue multi-AZ para alta disponibilidad, AWS Shield para protección DDoS, AWS WAF para seguridad de aplicaciones y estrategia completa de respaldo con AWS Backup.

Securización de infraestructura AWS con bastion host avanzado, 2FA y auditoría de accesos
Implementación de arquitectura de seguridad en AWS con bastion host como punto único de entrada, autenticación de dos factores con Google Authenticator, control de acceso basado en roles, túneles SSH cifrados para servicios internos y sistema completo de auditoría de sesiones de usuario para cumplimiento normativo.

Securización y bastionado de servidores AWS EC2 Ubuntu con arquitectura multi-volumen
Solución de bastionado automatizado para servidores AWS EC2 Ubuntu basada en arquitectura multi-volumen cifrada, controles de seguridad a nivel de sistema operativo, fortalecimiento SSH, gestión de accesos y monitorización integral. Proceso repetible mediante AMIs para múltiples entornos productivos.
Comentarios
Enviar comentario