Project Overview
Organizations operating globally distributed web applications face critical challenges ensuring consistent availability and performance for users worldwide. As an independent AWS cloud architect, I have designed and implemented comprehensive global load balancing and high availability solutions for multiple clients across different industries, each operating business-critical web applications and services with international user bases.

These organizations typically faced similar infrastructure limitations. Their services were concentrated in single availability zones, creating single points of failure that exposed their businesses to significant downtime risk. Additionally, users in different geographic regions experienced inconsistent latency, affecting overall user experience and operational efficiency.
For each client, I architected complete infrastructure transformations leveraging AWS Global Accelerator, Application Load Balancers, and multi-region deployment patterns to deliver enterprise-grade availability, resilience, and performance optimization tailored to their specific requirements and traffic patterns.
The Challenge: Overcoming Latency and Fragility
The initial state of the infrastructure for these clients was precarious. Running all services within a single availability zone created a significant single point of failure; a disruption in that specific data center could take the entire business offline. This lack of redundancy meant that any maintenance or unexpected issue required manual intervention and often resulted in service downtime.
Beyond availability, the global user experience was inconsistent. Users outside the primary region faced variable latency as their traffic traversed the public internet through multiple hops, leading to packet loss and jitter. Managing this environment was operationally complex. A critical business requirement from corporate clients was the ability to whitelist specific IP addresses for firewall access. The existing dynamic IP architecture made this impossible, creating friction during client onboarding. Additionally, without centralized management for SSL/TLS certificates, security compliance was difficult to maintain. The architecture needed to evolve from a fragile, single-server model to a robust, self-healing global platform.
Global Architecture and Traffic Flow
To address these challenges, I designed a multi-layered solution that optimizes traffic from the edge to the application. The architecture begins with AWS Global Accelerator, which serves as the entry point for all user traffic.
Why Global Accelerator instead of CloudFront?
While CloudFront is the standard for content delivery, it wasn’t the right fit for this specific workload. The platform relied heavily on dynamic content caching managed by a custom Varnish layer, as the custom cache layer implemented complex logic and advanced features beyond CloudFront’s standard capabilities. More importantly, the application ecosystem included not just web services but also TCP-based auxiliary services (SmartFoxServer) and UDP protocols for VoIP, which required protocol support beyond standard HTTP/HTTPS. Finally, the strict requirement for static Anycast IP addresses for client firewall whitelisting made Global Accelerator the definitive architectural choice.
By providing two static Anycast IP addresses, we simplified client firewall configurations significantly—these IPs remain constant regardless of the underlying infrastructure changes. This layer also includes AWS Shield protection by default, safeguarding the application against common network and transport layer DDoS attacks without additional configuration.
Traffic enters the AWS global network at the edge location nearest to the user, bypassing the congested public internet. This optimized routing immediately reduces latency and packet loss. From there, traffic is directed to the appropriate region (Ireland or Frankfurt) based on health and proximity.
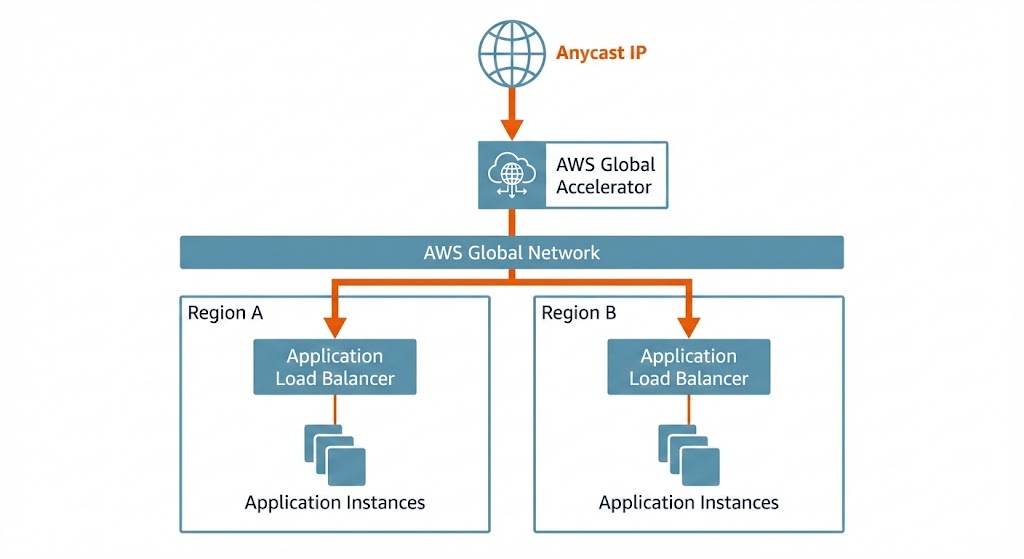
Inside the VPC, Application Load Balancers (ALB) and Network Load Balancers (NLB) handle the distribution of traffic across multiple Availability Zones (AZs). The ALBs manage HTTP/HTTPS traffic with intelligent routing rules based on host headers and paths, while centrally managing SSL/TLS certificates via AWS ACM. This setup ensures that encryption is handled efficiently and that traffic is securely routed to the correct application target groups.
Network Resilience
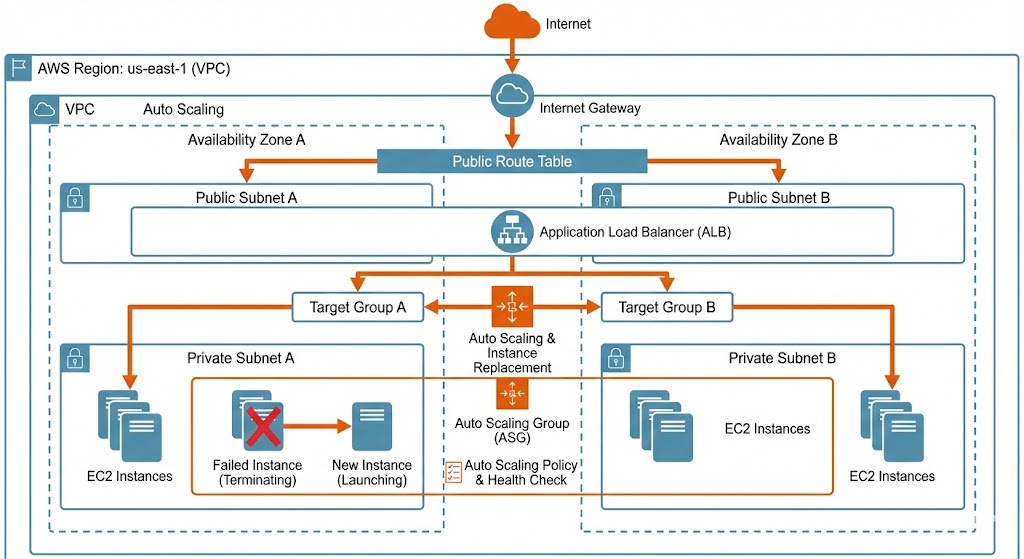
The underlying network was completely redesigned to support this high availability. Resources were distributed across three Availability Zones (AZ-1a, AZ-1b, AZ-1c) in the primary region, with internal service discovery managed via Amazon Route 53 private hosted zones. This Multi-AZ deployment ensures that even if an entire data center goes offline, the load balancers automatically redirect traffic to healthy instances in the remaining zones without service interruption.
For critical services, a secondary deployment in the Frankfurt region provides cross-region disaster recovery. This active-passive configuration guarantees that data and services remain available even in the unlikely event of a full regional outage.
Automated Resilience and Infrastructure Management
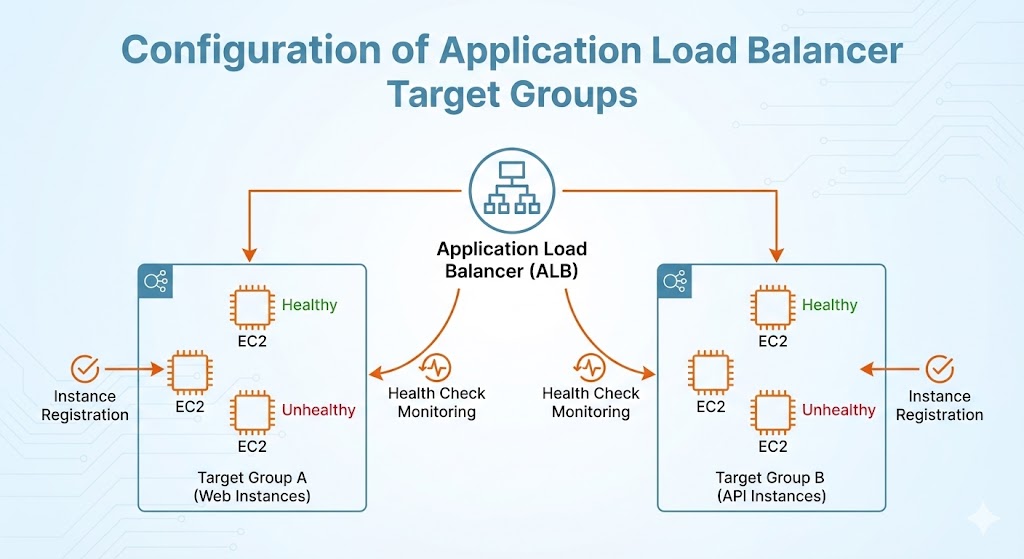
A key component of this architecture is its ability to “breathe” and adapt to changing conditions without human intervention. This resilience is achieved through Auto Scaling Groups integrated with Application Load Balancer health checks and Amazon CloudWatch monitoring.
Instead of maintaining a static fleet of servers, the system leverages CloudWatch metrics to monitor the health and performance of every instance. If a server fails a health check—whether due to a software crash or hardware issue—the Auto Scaling Group immediately removes it from rotation and launches a replacement. This self-healing capability ensures the application always maintains its required capacity.
The “web0” Golden Image Strategy
To ensure consistency across all dynamically created instances, I implemented a rigorous configuration management workflow using a “Golden Image” strategy. This approach of using Auto Scaling Groups with custom AMIs was specifically chosen because most of these clients’ existing applications were not designed for containerization. By leveraging Launch Templates and immutable AMIs, we achieved modern, automated scalability without the complexity and risk of refactoring entire application stacks for Docker or Kubernetes.
A dedicated staging instance, known as web0, serves as the master template for the entire fleet. This instance operates outside the production load balancers and is used exclusively for testing system-level changes, such as security patches or new application deployments. Once a configuration is validated on web0, an automated process generates a new Amazon Machine Image (AMI).
This new AMI is then referenced in the Launch Templates used by the Auto Scaling Groups. To roll out an update, we simply trigger an instance refresh. The Auto Scaling Groups gradually replace old instances with new ones running the updated AMI, ensuring a zero-downtime deployment process. This workflow guarantees that every server in production is identical, eliminating configuration drift and making the infrastructure immutable and predictable.
Results and Impact
The transformation of this infrastructure delivered immediate and measurable business value. By moving to a Multi-AZ architecture with Global Accelerator, we achieved a 99.99% uptime SLA, effectively eliminating service outages caused by infrastructure failures. The self-healing capabilities meant that the operations team no longer had to wake up at night to restart stuck servers; the system repaired itself.
Performance improvements were equally impressive. Global users experienced up to a 60% reduction in latency thanks to the optimized routing through the AWS backbone. The introduction of static Anycast IPs solved the operational headaches for corporate clients with strict firewalls, while the centralized certificate management improved the overall security posture.
Ultimately, this project turned a fragile, manual infrastructure into a resilient, automated, and globally scalable platform ready for future growth.
Need global high-availability architecture with automatic failover?
If your organization faces similar challenges:
- Single-region infrastructure vulnerable to complete outages from AWS regional failures.
- High latency for global users accessing your application from distant locations.
- Corporate firewall restrictions requiring static IP addresses for whitelisting.
- Manual server recovery during failures causing extended downtime and operational overhead.
- No DDoS protection leaving your application vulnerable to volumetric attacks.
As an AWS cloud architect with 20+ years of infrastructure experience, I can help you design and implement multi-region architectures with AWS Global Accelerator, automatic failover, self-healing Auto Scaling Groups, and comprehensive DDoS protection with AWS Shield.
Specialized in Global Accelerator implementation, Multi-AZ architectures, Application Load Balancers, and automated zero-downtime deployments.
Get in touch →

About the author
Daniel López Azaña
Tech entrepreneur and cloud architect with over 20 years of experience transforming infrastructures and automating processes. Specialist in AI/LLM integration, Rust and Python development, and AWS & GCP architecture. Restless mind, idea generator, and passionate about technological innovation and AI.
Related projects
Multilevel network security architecture in AWS with VPC, NAT Gateway and perimeter protection
Design and implementation of enterprise AWS security architecture with multilevel VPC, public and private subnet separation, NAT Gateway for controlled outbound traffic, multi-AZ deployment for high availability, AWS Shield for DDoS protection, AWS WAF for application security and comprehensive backup strategy with AWS Backup.

AWS Cloud Architecture Consulting - Enterprise Solutions for Multiple Industries
Independent AWS cloud architecture consulting providing strategic guidance and technical leadership in designing and implementing innovative cloud infrastructure solutions for diverse clients across multiple industries, specializing in architectural design, deployment, optimization, security, compliance, cost management and CI/CD practices.
Optimalway: AWS Infrastructure & Optimization
Scalable AWS infrastructure with auto-scaling for PHP/Java apps, MongoDB optimization, and Apache/PHP-FPM/Tomcat performance analysis. Trusted cloud partner.
Comments
Submit comment