El valor medio de carga es una métrica muy importante para comprender el comportamiento de un sistema Linux, y sobre todo su estado actual y en el pasado reciente. Muchas veces hay confusión entre su significado y el del porcentaje de uso de CPU, pero en realidad son importantes las diferencias. En este artículo trato de explicar el verdadero significado de ambos y cómo saber si una máquina Linux se encuentra sobrecargada o infrautilizada.
Valor medio de carga
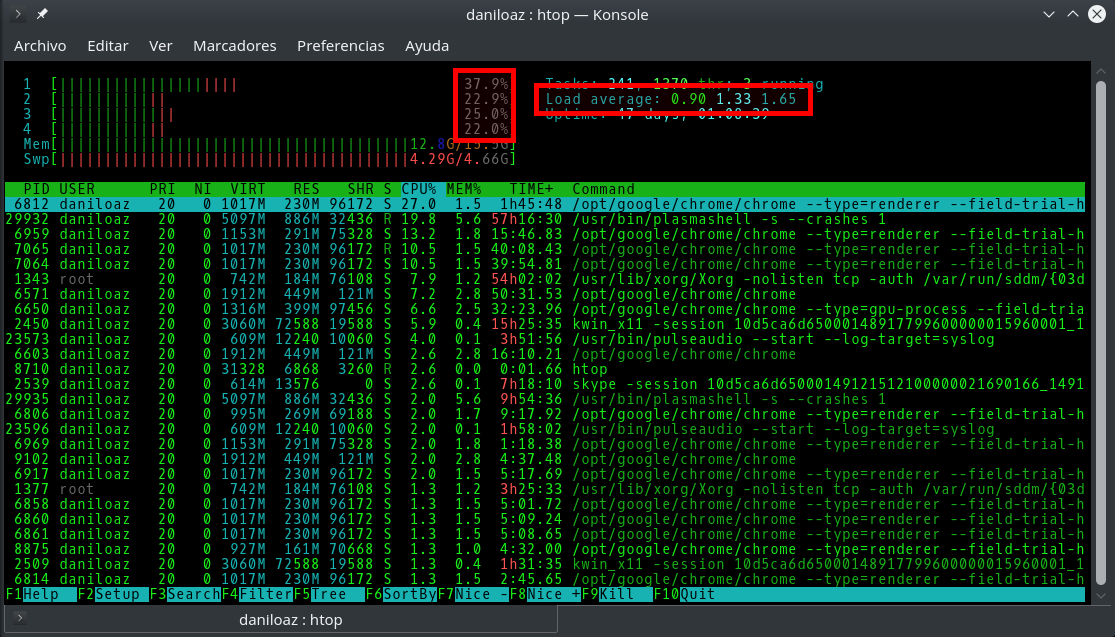
Se muestra en las distintas herramientas de monitorización (top, atop, htop, etc.) como un conjunto de 3 valores que representan la carga media de CPU que ha experimentado un sistema Linux en los últimos 1, 5 y 15 minutos respectivamente. Por tanto, una primera diferencia es que se trata de valores históricos, mientras que el porcentaje de utilización de la CPU se suele medir típicamente en intervalos de entre 1 y 5 segundos, por lo que su valor suele ser casi instantáneo.
Error: Your Requested widget " ai_widget-6" is not in the widget list.
- [do_widget_area above-nav-left]
- [do_widget_area above-nav-right]
- [do_widget_area footer-1]
- [do_widget id="wpp-4"]
- [do_widget_area footer-2]
- [do_widget id="recent-posts-4"]
- [do_widget_area footer-3]
- [do_widget id="recent-comments-3"]
- [do_widget_area footer-4]
- [do_widget id="archives-4"]
- [do_widget_area logo-bar]
- [do_widget id="oxywidgetwpml-3"]
- [do_widget_area menu-bar]
- [do_widget id="search-3"]
- [do_widget_area sidebar]
- [do_widget id="search-4"]
- [do_widget id="ai_widget-2"]
- [do_widget id="categories-5"]
- [do_widget id="ai_widget-3"]
- [do_widget id="ai_widget-4"]
- [do_widget id="ai_widget-5"]
- [do_widget_area sub-footer-1]
- [do_widget id="text-4"]
- [do_widget_area sub-footer-2]
- [do_widget_area sub-footer-3]
- [do_widget_area sub-footer-4]
- [do_widget_area upper-footer-1]
- [do_widget id="search-2"]
- [do_widget id="recent-posts-2"]
- [do_widget id="recent-comments-2"]
- [do_widget id="archives-2"]
- [do_widget id="categories-2"]
- [do_widget id="meta-2"]
- [do_widget_area upper-footer-2]
- [do_widget_area upper-footer-3]
- [do_widget_area upper-footer-4]
- [do_widget_area widgets_for_shortcodes]
- [do_widget id="search-5"]
- [do_widget id="ai_widget-6"]
- [do_widget_area wp_inactive_widgets]
- [do_widget id="wpp-2"]
- [do_widget id="text-1"]
- [do_widget id="recent-posts-3"]
- [do_widget id="categories-3"]
- [do_widget id="archives-3"]
- [do_widget id="icl_lang_sel_widget-3"]
El valor de carga de CPU representa en Linux el número medio de trabajos (leáse conjunto de instrucciones de un programa en lenguaje máquina correspondientes a un hilo de ejecución de un proceso) que se encuentran en ejecución (running state), encolados (runnable state) o, muy importante, dormidos pero no interrumpibles (uninterrumpible sleep state). Es decir, para calcular el valor de carga de CPU se tienen en cuenta los procesos que se encuentran corriendo o a la espera de que se les asigne tiempo de CPU. Los procesos dormidos (sleep state), zombies, o parados no se consideran.
PROCESS STATE CODES
R running or runnable (on run queue)
D uninterruptible sleep (usually IO)
S interruptible sleep (waiting for an event to complete)
Z defunct/zombie, terminated but not reaped by its parent
T stopped, either by a job control signal or because
it is being traced
[…]

Este sería el significado de distintos valores de carga en un sistema de un único procesador y un solo core/núcleo:
- 0.00: no hay ningún trabajo ni en ejecución ni a la espera de ser ejecutado por la CPU, es decir, la CPU de encuentra completamente ociosa (idle). Así, si un programa en ejecución (proceso) necesita realizar una tarea, se lo solicita al sistema operativo y éste le asigna instantáneamente tiempo de CPU porque no hay ningún otro proceso compitiendo por ella.
- 0.50: no hay ningún trabajo en espera, pero la CPU si está procesando trabajos y lo está haciendo al 50% de su capacidad. En esta situación el sistema operativo también podría asignar tiempo de CPU instantáneamente a otros procesos sin necesidad de ponerlos en espera.
- 1.00: no hay trabajos encolados pero la CPU se encuentra procesando trabajos al 100% de su capacidad, por lo que si un nuevo proceso solicita tiempo de CPU éste tendrá que ser puesto en espera hasta que otro trabajo se complete o hasta que expire el tiempo de CPU asignado a otro proceso (CPU tick) y el sistema operativo decida cuál es el siguiente en función por ejemplo de su prioridad.
- 1.50: la CPU se encuentra trabajando al 100% de su capacidad y 5 de cada 15 trabajos que solicitan tiempo de CPU, es decir, el 33,33%, han de encolarse a la espera de que otros agoten su tiempo asignado. Por tanto, en cuanto se supera el umbral de 1.0 se puede decir que el sistema está sobrecargado, pues no puede atender inmediatamente el 100% de los trabajos que se le solicitan.
Sistemas multiprocesador o multicore
En sistemas con múltiples procesadores o núcleos (varias CPUs lógicas), el significado de los distintos valores de carga varía en función del número de procesadores presentes en el sistema. Así, una máquina con 4 procesadores no estará siendo utilizada al 100% hasta que alcance una carga de 4.00, por lo que lo primero que tenemos que hacer a la hora de interpretar los 3 valores de carga que nos ofrecen los comandos top, htop o uptime es dividirlos entre el número de CPUs lógicas presentes en nuestro sistema, y a partir de ahí sacar conclusiones.
Porcentaje de utilización de la CPU
Si observamos los diferentes procesos que van pasando por la CPU durante un intervalo de tiempo dado, el porcentaje de utilización representaría la fracción de tiempo respecto a ese intervalo que la CPU ha estado ejecutando instrucciones correspondientes a dicho proceso. Pero para este cálculo sólo se tienen en cuenta los procesos en ejecución (running), no los que están en espera, ya estén encolados o dormidos pero no interrumpibles (por ejemplo esperando la finalización de una operación de entrada/salida).
Error: Your Requested widget " ai_widget-6" is not in the widget list.
- [do_widget_area above-nav-left]
- [do_widget_area above-nav-right]
- [do_widget_area footer-1]
- [do_widget id="wpp-4"]
- [do_widget_area footer-2]
- [do_widget id="recent-posts-4"]
- [do_widget_area footer-3]
- [do_widget id="recent-comments-3"]
- [do_widget_area footer-4]
- [do_widget id="archives-4"]
- [do_widget_area logo-bar]
- [do_widget id="oxywidgetwpml-3"]
- [do_widget_area menu-bar]
- [do_widget id="search-3"]
- [do_widget_area sidebar]
- [do_widget id="search-4"]
- [do_widget id="ai_widget-2"]
- [do_widget id="categories-5"]
- [do_widget id="ai_widget-3"]
- [do_widget id="ai_widget-4"]
- [do_widget id="ai_widget-5"]
- [do_widget_area sub-footer-1]
- [do_widget id="text-4"]
- [do_widget_area sub-footer-2]
- [do_widget_area sub-footer-3]
- [do_widget_area sub-footer-4]
- [do_widget_area upper-footer-1]
- [do_widget id="search-2"]
- [do_widget id="recent-posts-2"]
- [do_widget id="recent-comments-2"]
- [do_widget id="archives-2"]
- [do_widget id="categories-2"]
- [do_widget id="meta-2"]
- [do_widget_area upper-footer-2]
- [do_widget_area upper-footer-3]
- [do_widget_area upper-footer-4]
- [do_widget_area widgets_for_shortcodes]
- [do_widget id="search-5"]
- [do_widget id="ai_widget-6"]
- [do_widget_area wp_inactive_widgets]
- [do_widget id="wpp-2"]
- [do_widget id="text-1"]
- [do_widget id="recent-posts-3"]
- [do_widget id="categories-3"]
- [do_widget id="archives-3"]
- [do_widget id="icl_lang_sel_widget-3"]
Por tanto, esta métrica nos puede dar una idea de cuáles son los procesos que más exprimen una CPU, pero no nos aporta un retrato fiel sobre el verdadero estado del sistema, si está sobrecargado o si se está siendo infrautilizado.
Ojo con las operaciones de entrada/salida (I/O)
He destacado al principio como muy importante el estado dormido pero no interrumpible (uninterruptible sleep state), pues a veces podremos encontrar unos valores de carga extraordinariamente altos y sin embargo ver como los distintos procesos de la máquina presentan un porcentaje de utilización relativamente bajo. Si no tenemos en cuenta este estado nos resultará inexplicable la situación y no sabremos como abordarla. Un proceso presenta este estado cuando se encuentra a la espera de la liberación de algún recurso y su ejecución no puede ser interrumpida, por ejemplo cuando espera a que finalice una operación de entrada/salida (I/O) no interrumpible (no todas los son). Normalmente esta situación se produce ante fallos de disco o de sistemas de ficheros en red como NFS, o por estar haciendo un uso intensivo de algún dispositivo muy lento, por ejemplo USB 1.0.
Ante este escenario tendremos que recurrir a herramientas alternativas como iostat o iotop, las cuales nos indicarán cuáles son los procesos que están realizando un mayor número de operaciones de E/S, de forma que podamos matar dichos procesos o asignarles menos prioridad (comando nice) para poder asignar más tiempo de CPU a otros procesos más críticos.
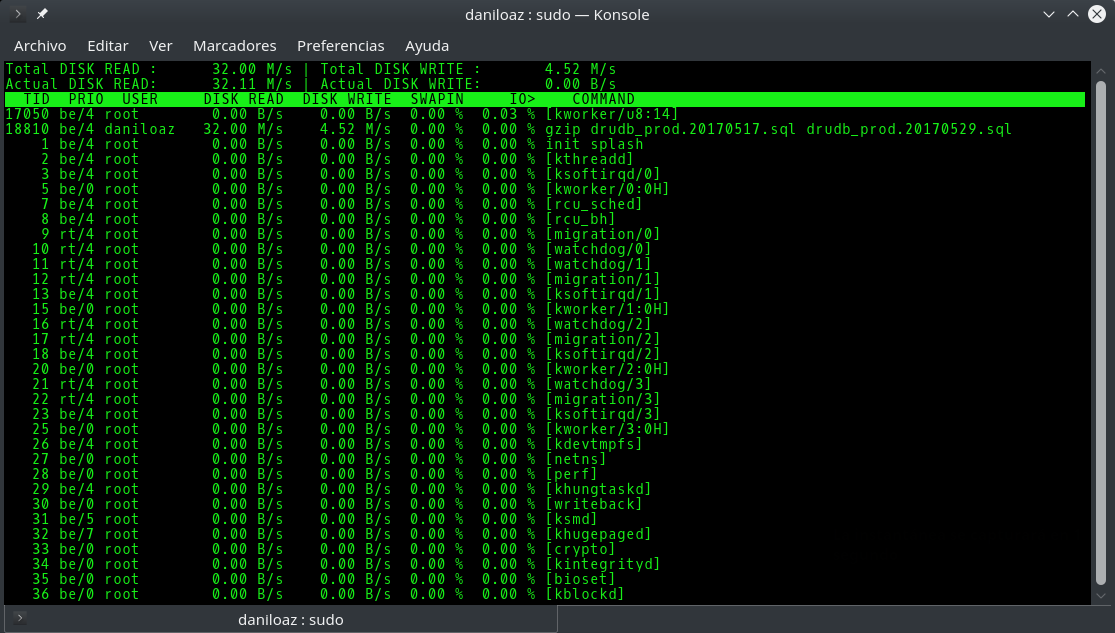
iotop
Algunos consejos
Que el sistema se sobrecargue y supere valores de carga de 1.0 en momentos puntuales no supone un problema, pues aun con algo de demora la CPU procesará los trabajos encolados y la carga volverá a disminuir a valores por debajo de 1.0. Pero si el sistema presenta valores sostenidos de carga por encima de 1 quiere decir que no es capaz de absorber toda la carga que se le impone, sus tiempos de respuesta aumentarán, y el sistema se mostrará en general lento e incapaz. Valores altos por encima de 1 sobre todo en las medias de carga de los últimos 5 y 15 minutos son un claro síntoma de que o bien necesitamos mejorar el hardware de nuestra máquina, o exigirle menos ya sea acotando el uso que pueden hacer de ella los usuarios o repartiendo la carga entre múltiples máquinas similares.
Así, haría las siguientes recomendaciones:
- >= 0.70: no pasa nada pero es necesario vigilar, y si se mantiene en el tiempo hay que investigar antes de que la cosa vaya a peor.
- >= 1.00: hay un problema y tienes que encontrarlo y solucionarlo, ya que de lo contrario un pico importante de carga en el sistema hará que tus aplicaciones se vuelvan lentas o que no respondan.
- >= 3.00: tu sistema se muestra desesperadamente lento. Es incluso difícil manejarnos desde la línea de comandos para tratar de hallar la causa del problema, por lo que nos llevará más tiempo solucionarlo que si hubiéramos actuado antes. Corremos el riesgo de que el sistema se sature aún más y se nos caiga definitivamente.
- >= 5.00: es probable que no seamos capaces de recuperar el sistema. Podemos esperar a que por un milagro baje la carga de forma espontánea, o si sabemos lo que ha pasado y nos lo podemos permitir, podemos dejar lanzado en la consola un comando tipo pkill -9 <nombre_proceso> y rezar para que en algún momento se llegue a ejecutar y podamos aliviar así la carga del sistema. Si no seguramente no nos quedé más opción que reiniciar la máquina con el típico botonazo.
2 comentarios
Unirte a la conversaciónSusana Robledo - 25/09/2019
Hola Daniel, quisiera consultarte por un servidor que aparentemente tiene 4 cores pero los valores del load average a veces supera el valor 15! y el valor del ultimo minuto jamas esta por debajo de 4, es normal esto?. Muchas gracias. Paso el contenido de /etc/cpuinfo:
Promedio de carga: 7.03(1 min), 6.45(5 min), 7.61(15 min)
Procesos running/total: 57/1346, ult proceso Id: 3279665
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 60
model name : Intel(R) Xeon(R) CPU E3-1230 v3 @ 3.30GHz
stepping : 3
microcode : 39
cpu MHz : 3299.765
cache size : 8192 KB
physical id : 0
siblings : 8
core id : 0
cpu cores : 4
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology nonstop_tsc aperfmperf cpuid_faulting pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm ida arat epb pln pts dtherm invpcid_single tpr_shadow vnmi flexpriority ept vpid fsgsbase bmi1 hle avx2 smep bmi2 erms invpcid rtm xsaveopt
bogomips : 6599.53
clflush size : 64
cache_alignment : 64
address sizes : 39 bits physical, 48 bits virtual
Daniel - 20/01/2020
No debería ser lo normal, esos valores de carga indican que tu servidor está bastante sobrecargado. O aumentas el nº de CPU’s, o repartes las carga entre más servidores, o disminuyes la carga en el servidor (reduciendo el nº de procesos, el nº de peticiones recibidas, I/O, etc.). Esas son básicamente las opciones que tienes.