En enero de 2019, me contactaron para algo que parecía rutinario: auditar la infraestructura Linux de una empresa comercial. Lo que descubrí durante esas primeras horas de análisis cambiaría completamente el rumbo del proyecto. Los servidores ocultaban secretos que ni siquiera el cliente conocía.
Semanas después, cuando un corte eléctrico dejó el ERP y la centralita fuera de línea, esos secretos se convertirían en la diferencia entre una recuperación en 45 minutos o días de interrupción comercial.
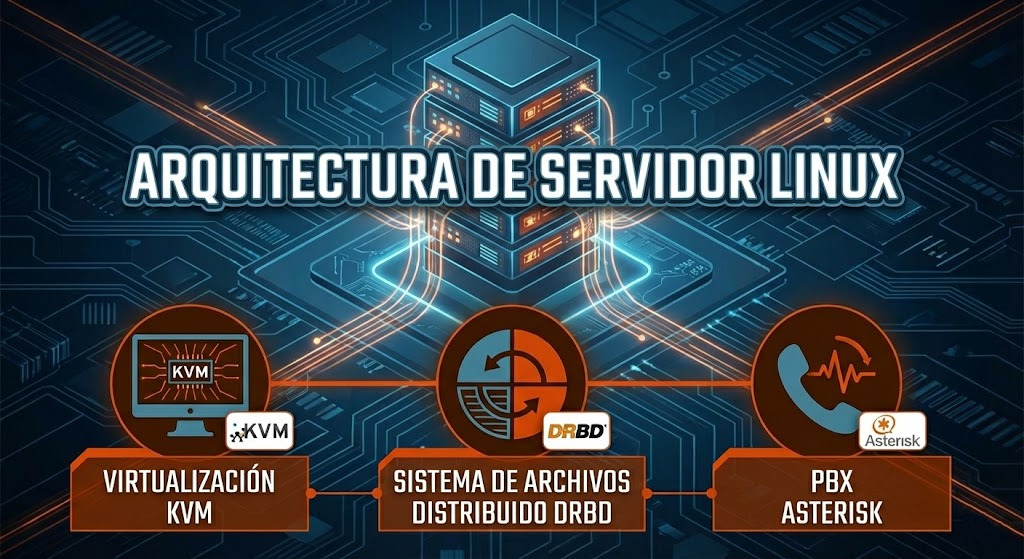
El escenario: cuando la falta de documentación es el problema
El cliente necesitaba traspasar el mantenimiento de servidores críticos de su proveedor saliente. Se trataba de una empresa comercial con tienda física. El escenario inicial era desconcertante: documentación técnica prácticamente inexistente, configuraciones sin explicar y la sensación de que algo importante faltaba en el puzzle.
Mi misión era clara: descubrir qué había realmente, documentarlo todo y evaluar si la infraestructura podía continuar o necesitaba migración urgente.
Debian Wheezy sin actualizaciones de seguridad desde mayo de 2018. Más de un año de vulnerabilidades sin parchar.
Sin mapas de red, sin diagramas de servicios, sin procedimientos de recuperación. Todo por descubrir.
El descubrimiento: nada era lo que parecía
Cuando “servidor de correo” significa otra cosa completamente distinta
El primer servidor que analicé supuestamente gestionaba el correo. Pero a los 15 minutos de investigación, algo no cuadraba. Postfix estaba instalado, sí, pero solo reenviaba mensajes internos. No había servicio IMAP, no había buzones de usuario. ¿Dónde estaba el correo real?
Lo que sí encontré fue mucho más interesante: una máquina virtual Windows XP ejecutándose sobre KVM con un sistema de ficheros distribuido DRBD que en teoría replicaba a un servidor secundario… que estaba apagado.
El momento “ajá”
Un servidor Linux ejecutando una máquina virtual Windows XP con un ERP crítico, sobre un sistema de ficheros distribuido… cuyo nodo secundario llevaba meses inactivo. La “alta disponibilidad” era una ilusión.
| Componente | Configuración descubierta |
|---|---|
| Hardware | Dell PowerEdge R210 II, Intel i3-2100, 4GB RAM |
| Virtualización | KVM ejecutando Windows XP para el ERP |
| Almacenamiento | DRBD montado en /var/kvm-images/0 |
| Problema crítico | Nodo DRBD secundario inoperativo, sin redundancia real |
| Sistema operativo | Debian Wheezy (sin soporte desde mayo 2018) |
Documenté el comando exacto de arranque de la máquina virtual. Esto resultaría ser crítico semanas después, cuando el sistema colapsara y tuviera que levantarlo manualmente en plena crisis.
La centralita: Asterisk al límite
El segundo servidor era más directo: una centralita Asterisk con MySQL gestionando extensiones y registros de llamadas. Funcionaba, pero corría sobre el mismo Debian Wheezy obsoleto. La infraestructura telefónica de toda la empresa dependía de software sin actualizaciones de seguridad durante más de un año.
El servidor fantasma: cuando encuentras lo que nadie sabía que existía
Pero el correo seguía siendo un misterio. Los registros MX del dominio apuntaban a una IP, pero ese servidor Linux no tenía IMAP ni POP3 escuchando. Los logs de Postfix mostraban solo reenvíos internos. ¿Dónde demonios estaba el correo real?
Pasé días investigando, verificando configuraciones, analizando tráfico de red. Finalmente, confronté con los hechos: “Este servidor no gestiona el correo. Tiene que haber otro servidor en algún lugar.”
El momento de la verdad
”Finalmente descubrimos que había un cuarto servidor en las instalaciones del cliente… El servicio de correo utiliza Postfix como MTA y Dovecot como MDA/LDA y auth, con MySQL como backend.”
— Respuesta tras verificar físicamente las instalaciones
Esto salvó el proyecto. Si hubiera asumido que el primer servidor gestionaba el correo y hubiera empezado una migración, habría tumbado el correo de toda la empresa. La investigación exhaustiva evitó un desastre.
Con toda la infraestructura documentada, entregué un informe completo con recomendaciones claras: migrar el correo a la nube, mantener Asterisk pero planificar su actualización, y sobre todo, ser conscientes de que la “alta disponibilidad” DRBD era ficción.
Cuando llega la crisis: 45 minutos para salvar una empresa
21 de febrero de 2019, 9:30 AM
Un corte eléctrico tumbó todos los servidores. Cuando la luz volvió, nada arrancó automáticamente. El ERP que gestionaba toda la tienda: caído. La centralita que manejaba las llamadas comerciales: muda. La empresa estaba paralizada.
Me llamaron con urgencia. La voz al otro lado del teléfono transmitía preocupación real: “Necesitamos esto funcionando ya. Cada hora que pasa son ventas perdidas.”
Cuando la documentación encuentra la urgencia
Haber documentado todo exhaustivamente durante la auditoría me permitió identificar rápidamente qué revisar y dónde podría estar el problema. Sin ese trabajo previo, solucionar esto habría llevado mucho más tiempo.
Problema 1: El ERP invisible
El diagnóstico fue rápido: el sistema de ficheros DRBD no se montaba automáticamente porque alguien había comentado la línea en /etc/fstab. Sin el disco montado, KVM no podía arrancar la máquina virtual Windows XP que contenía el ERP Sage.
Gracias a mi documentación exhaustiva de semanas antes, sabía exactamente qué hacer:
/etc/fstabRestaurar la línea que montaba automáticamente el dispositivo DRBD
Ejecutar mount /dev/drbd0 /var/kvm-images/0
Usar el comando exacto documentado en la auditoría
30 minutos desde la llamada hasta tienda funcionando
Problema 2: La centralita amnésica
Con el ERP levantado, quedaba la centralita. El problema aquí era diferente: Asterisk había cambiado su IP por DHCP. De 10.100.100.119 pasó a 192.168.1.52. Todos los teléfonos de la oficina estaban configurados estáticamente para conectarse a la IP original. Ningún teléfono funcionaba.
Reconfigurar cada terminal habría llevado horas. La solución elegante fue crear una interfaz virtual con la IP original:
ip addr add 10.100.100.119/24 dev eth0:0Elegancia bajo presión
El servidor respondía ahora en ambas IPs simultáneamente. Los teléfonos seguían conectando a su IP configurada, y todo funcionó sin tocar un solo terminal. 15 minutos desde diagnóstico hasta centralita completamente operativa.
El resultado: 45 minutos y dos servicios salvados
Auditoría: descubrí un cuarto servidor no documentado y evité una migración desastrosa. Identifiqué sistemas críticos ejecutándose sobre infraestructura obsoleta y sin redundancia real.
Crisis: cuando el corte eléctrico tumbó todo, la documentación exhaustiva convirtió lo que podrían haber sido días de interrupción en 45 minutos de recuperación quirúrgica.
Lección: en infraestructura crítica, la documentación meticulosa y el conocimiento profundo no son lujos, son la diferencia entre una empresa operando y una empresa paralizada.
Lo que aprendimos (y lo que salvó el día)
¿Tu infraestructura está lista para una crisis?
Si tu empresa depende de sistemas críticos:
- Auditorías de infraestructura que descubren lo que realmente tienes (incluso servidores ocultos)
- Documentación exhaustiva que convierte recuperaciones de días en minutos
- Recuperación ante desastres cuando cada minuto cuenta y la empresa está paralizada
- Análisis forense de sistemas legacy con arquitecturas complejas sin documentar
- Recomendaciones de modernización para migrar a cloud sin interrumpir operaciones
Con más de 20 años de experiencia en administración de sistemas Linux, convierto infraestructuras sin documentar en sistemas conocidos, predecibles y recuperables.
Especializado en virtualización KVM, sistemas de ficheros distribuidos, centralitas Asterisk y recuperación de emergencia cuando los segundos cuentan.
Ponte en contacto →

Sobre el autor
Daniel López Azaña
Emprendedor tecnológico y arquitecto cloud con más de 20 años de experiencia transformando infraestructuras y automatizando procesos. Especialista en integración de IA/LLM, desarrollo con Rust y Python, y arquitectura AWS & GCP. Mente inquieta, generador de ideas y apasionado por la innovación tecnológica y la IA.
Proyectos relacionados
Optimalway: infraestructura AWS y optimización
Infraestructura AWS escalable con autoescalado para PHP y Java, optimización MongoDB y análisis rendimiento Apache/PHP-FPM/Tomcat. Partner cloud de confianza.
Plataforma de subastas de coches en vivo - Sistema de pujas en tiempo real con WebSockets
Aplicación web completa para gestionar subastas de coches simultáneas presenciales y online, con motor de pujas en tiempo real basado en websockets, interfaz responsive multidispositivo y sistema integral de administración, desarrollada con AngularJS, Symfony e infraestructura AWS.

Plataforma de moda Trendmii - Sitio web de e-commerce completo con CMS personalizado
Plataforma full-stack de e-commerce de moda para startup Trendmii, construida con Yii Framework con diseño responsive, sistema de blog personalizado, panel de administración completo con tema Ace Admin, soporte multiidioma para inglés y español, integración de autenticación social, y consultoría de marketing online. Desarrollo de 6 meses entregando solución completa de marketplace de moda.
Comentarios
Enviar comentario