DevSecOps & SRE
Build resilient, secure, and highly available systems with modern DevOps practices and SRE expertise
- What is DevOps & SRE?
- DevOps is a set of practices combining software development (Dev) and IT operations (Ops) to shorten the development lifecycle and deliver high-quality software continuously. Site Reliability Engineering (SRE) applies software engineering principles to infrastructure and operations, focusing on reliability, scalability, and automation. Together, they enable organizations to deploy faster, reduce failures, and maintain highly available systems through CI/CD pipelines, infrastructure as code, and observability practices.

Streamline your software delivery and operations with DevSecOps and Site Reliability Engineering (SRE) best practices that accelerate deployment velocity while ensuring 99.99% uptime. I design and implement complete CI/CD pipelines using GitHub Actions, GitLab CI, Jenkins, and ArgoCD, integrating security at every stage with automated vulnerability scanning, secret management, and compliance checks. My approach combines development speed with operational excellence, reducing deployment time from weeks to minutes.
I specialize in Kubernetes orchestration on AWS (EKS), Google Cloud (GKE), and on-premises clusters, implementing GitOps workflows with Flux and ArgoCD for declarative infrastructure management. My Infrastructure as Code (IaC) expertise includes Terraform and Pulumi for multi-cloud deployments, Ansible for configuration management, and Helm charts for application packaging. I implement comprehensive observability using the Prometheus/Grafana stack, OpenTelemetry, Datadog, and the ELK stack (Elasticsearch, Logstash, Kibana) for real-time monitoring and troubleshooting.
Whether you need to modernize legacy infrastructure, implement zero-downtime deployments, or establish SRE practices with SLOs, error budgets, and incident management, I deliver robust solutions. From container orchestration to chaos engineering, I build systems that self-heal, scale automatically, and provide the reliability your business demands.
CI/CD Pipeline Design
- Complete pipeline automation with GitHub Actions, GitLab CI, Jenkins
- GitOps workflows with ArgoCD and Flux for declarative deployments
- Zero-downtime deployments with blue-green and canary strategies
- Automated testing integration (unit, integration, e2e, load tests)
Container Orchestration
- Kubernetes clusters on AWS EKS, Google GKE, Azure AKS, on-prem
- Helm charts for application packaging and release management
- Service mesh implementation with Istio, Linkerd for traffic management
- Auto-scaling (HPA, VPA, Cluster Autoscaler) for cost optimization
Infrastructure as Code
- Terraform for multi-cloud infrastructure provisioning (AWS, GCP, Azure)
- Ansible for configuration management and application deployment
- Pulumi for infrastructure with TypeScript, Python, Go, C#
- CloudFormation for AWS-native infrastructure management
Observability & Monitoring
- Prometheus & Grafana for metrics collection and visualization
- OpenTelemetry for distributed tracing and metrics
- ELK Stack (Elasticsearch, Logstash, Kibana) for centralized logging
- Datadog, New Relic integration for APM and infrastructure monitoring
Security Integration (DevSecOps)
- SAST/DAST security scanning (SonarQube, Snyk, Trivy, Clair)
- Secret management with Vault, AWS Secrets Manager, Sealed Secrets
- Container security scanning and hardening (Falco, Aqua Security)
- Compliance automation (CIS benchmarks, PCI-DSS, HIPAA)
SRE Practices & Incident Management
- SLO/SLI definition and error budget management
- Incident management workflows (PagerDuty, Opsgenie integration)
- Chaos engineering for resilience testing (Chaos Monkey, Litmus)
- Post-mortem analysis and continuous improvement processes
DevSecOps & SRE Tools & Technologies
CI/CD & Automation
Container & Orchestration
Monitoring & Observability
Security Tools
Business Impact of DevSecOps & SRE
Reduce deployment time from weeks to minutes with automated CI/CD
Achieve 99.99% uptime with SRE best practices and proactive monitoring
Cut infrastructure costs by 40% with container orchestration and auto-scaling
Detect and fix security vulnerabilities before production deployment
Reduce MTTR (Mean Time To Recovery) by 80% with automated incident response
Scale effortlessly from 100 to 100,000+ users with cloud-native architecture
Why Work With Me
Direct access to 20+ years of hands-on expertise
20+ Years Experience
Two decades of real-world experience designing, building, and optimizing production systems for startups and enterprises alike.
AWS & GCP Certified
Certified cloud architect with deep expertise in AWS and Google Cloud Platform, ensuring best practices and optimal solutions.
Hands-On Technical Expert
I write code, configure infrastructure, and solve problems directly—no delegation to junior staff or outsourcing.
Proven Results
Track record of reducing infrastructure costs by 40-60%, improving performance, and delivering projects on time.
Direct Communication
Work directly with me—no account managers or intermediaries. Clear, technical discussions with fast response times.
Bilingual Support
Fluent in English and Spanish, serving clients across Europe, Americas, and worldwide with no communication barriers.
Frequently Asked Questions
Common questions about DevSecOps and SRE services
DevOps is a set of practices that combines software development (Dev) and IT operations (Ops) to shorten the development lifecycle and deliver high-quality software continuously. Unlike traditional IT where development and operations work in silos with lengthy handoffs, DevOps emphasizes collaboration, automation, and shared responsibility. This approach eliminates bottlenecks, reduces manual errors, and enables teams to deploy changes multiple times per day instead of monthly or quarterly releases.
DevOps delivers transformative benefits including 200x faster deployment frequency, 24x faster recovery from failures, and 3x lower change failure rate. Organizations see reduced time-to-market, improved collaboration between teams, higher software quality through automated testing, and significant cost savings from automation. DevOps also improves employee satisfaction by reducing repetitive manual tasks and enabling teams to focus on innovation rather than firefighting.
A CI/CD pipeline automates the software delivery process from code commit to production deployment. When developers push code, the pipeline automatically triggers builds, runs unit and integration tests, performs security scans, and deploys to staging environments. After validation, changes can be automatically or manually promoted to production. This continuous flow ensures every change is tested, validated, and deployable, reducing risk and enabling rapid iteration.
DevOps practices benefit organizations of all sizes. Startups gain speed and efficiency from the start, avoiding technical debt. Mid-size companies typically see the highest ROI as they scale operations without proportionally increasing headcount. Enterprises benefit from breaking down silos and accelerating transformation initiatives. Even small teams of 3-5 developers can implement basic CI/CD pipelines that save hours of manual work weekly.
DevOps implementation costs vary based on scope and current maturity. A basic CI/CD pipeline setup typically ranges from $5,000-15,000, while comprehensive enterprise transformations can be $50,000-200,000+. However, the ROI is substantial—organizations typically save 20-40% on operational costs through automation, faster releases, and reduced downtime. I provide phased implementations that deliver value incrementally, so you see returns before the full investment is complete.
A complete DevOps transformation typically occurs in phases over 6-18 months. Phase 1 (1-2 months) establishes foundational CI/CD pipelines and version control practices. Phase 2 (2-4 months) adds automated testing, infrastructure as code, and monitoring. Phase 3 (3-6 months) implements advanced practices like GitOps, security automation, and SRE. Each phase delivers immediate value while building toward full maturity. Quick wins are visible within the first 2-4 weeks.
Essential DevOps tools include version control (Git), CI/CD platforms (GitHub Actions, GitLab CI, Jenkins), containerization (Docker), and infrastructure as code (Terraform, Ansible). Your team needs skills in scripting, cloud platforms (AWS, GCP, Azure), and a collaborative mindset. I provide hands-on training and documentation so your team can maintain and evolve the systems independently. Most teams become self-sufficient within 3-6 months.
DevOps focuses on collaboration between development and operations teams to automate software delivery. DevSecOps extends this by integrating security practices throughout the entire pipeline—from code commit to production. This means automated security scanning, vulnerability detection, compliance checks, and secure coding practices are built into every stage, rather than being an afterthought. I implement DevSecOps to ensure your applications are secure by design.
With mature DevOps practices, organizations typically achieve daily or even hourly deployments compared to monthly or quarterly releases. Reliability improves dramatically—deployment success rates exceed 99%, and mean time to recovery (MTTR) drops from hours to minutes. My clients commonly achieve 99.9-99.99% uptime through automated rollbacks, canary deployments, and comprehensive monitoring. These metrics are tracked and improved continuously.
I implement comprehensive monitoring and alerting systems that enable 99.99% uptime (less than 53 minutes downtime per year). This includes application performance monitoring (APM), infrastructure metrics, log aggregation, and synthetic monitoring. SLOs (Service Level Objectives) are defined with your business requirements, and error budgets guide deployment decisions. Automated incident response and on-call procedures ensure rapid detection and resolution of issues.
Getting started begins with a DevOps maturity assessment where I evaluate your current practices, infrastructure, and team capabilities. Within 1-2 weeks, you receive a prioritized roadmap with quick wins and long-term improvements. Implementation typically starts with establishing CI/CD pipelines for your most critical applications. I offer flexible engagement models—from full implementation to advisory support—tailored to your needs and budget.
I specialize in the complete DevOps toolchain: CI/CD with GitHub Actions, GitLab CI, and Jenkins; container orchestration with Docker and Kubernetes (EKS, GKE, AKS); infrastructure as code with Terraform, Pulumi, and Ansible; monitoring with Prometheus, Grafana, and Datadog; and security tools like Vault, Trivy, and SonarQube. I am cloud-agnostic but have deep expertise in AWS, including advanced services like EKS, Lambda, and CloudFormation.
Related Projects
Real-world implementations demonstrating this expertise
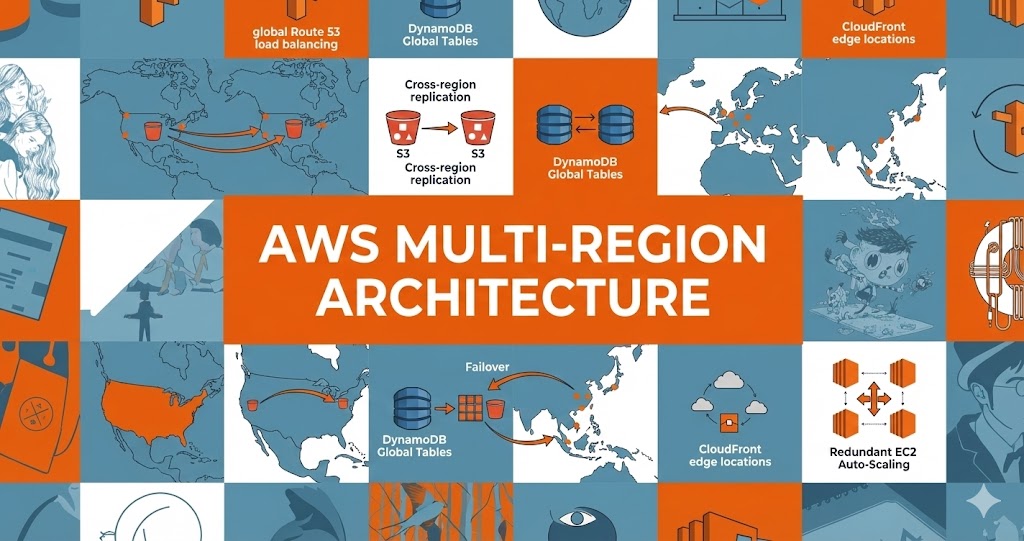
Domestika: DevOps & Cloud Infrastructure Transformation
Led complete infrastructure modernization for a fast-growing creative learning platform, implementing multi-region AWS architecture and comprehensive DevOps automation that supported the company's growth from 20 employees to unicorn status.
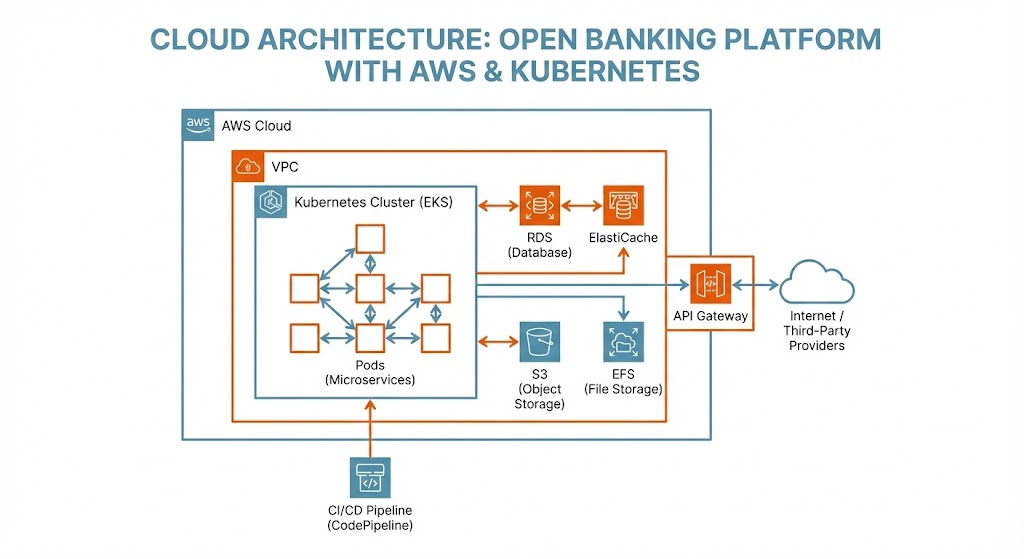
Cloud Infrastructure Migration for Open Banking Platform (Eurobits/Tink/Visa)
Management of complete infrastructure migration from on-premise to cloud (IBM Cloud and AWS) for an Open Banking platform. Design of modern cloud architectures, migration of hundreds of servers, and legacy infrastructure support during transformation process in a highly regulated international environment.

AWS Global Load Balancing and High Availability Architecture
Designed and implemented multi-region, highly available infrastructure leveraging AWS Global Accelerator and Application Load Balancers to achieve optimal latency, geographic distribution, and automatic failover capabilities across multiple availability zones.

Your expert
Daniel López Azaña
Cloud architect and AI specialist with over 20 years of experience designing scalable infrastructures and integrating cutting-edge AI solutions for enterprises worldwide.
Learn more